

Which type is x? Why?
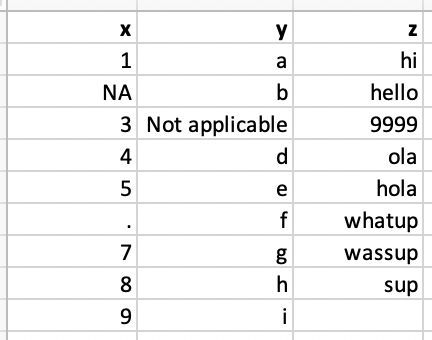
read_csv("data/df-na.csv")## # A tibble: 9 × 3## x y z ## <chr> <chr> <chr> ## 1 1 a hi ## 2 <NA> b hello ## 3 3 Not applicable 9999 ## 4 4 d ola ## 5 5 e hola ## 6 . f whatup## 7 7 g wassup## 8 8 h sup ## 9 9 i <NA>Option 1. Explicit NAs
read_csv("data/df-na.csv", na = c("", "NA", ".", "9999", "Not applicable"))
## # A tibble: 9 × 3## x y z ## <dbl> <chr> <chr> ## 1 1 a hi ## 2 NA b hello ## 3 3 <NA> <NA> ## 4 4 d ola ## 5 5 e hola ## 6 NA f whatup## 7 7 g wassup## 8 8 h sup ## 9 9 i <NA>Favourite foods
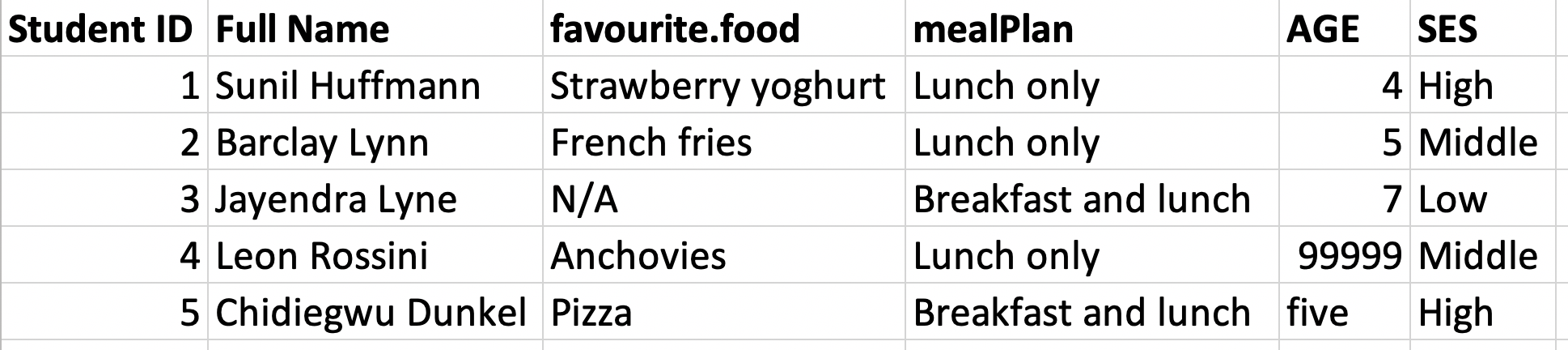
Favourite foods
fav_food <- read_excel("data/favourite-food.xlsx")fav_food## # A tibble: 5 × 6## `Student ID` `Full Name` favourite.food mealPlan AGE SES ## <dbl> <chr> <chr> <chr> <chr> <chr>## 1 1 Sunil Huffmann Strawberry yo… Lunch o… 4 High ## 2 2 Barclay Lynn French fries Lunch o… 5 Midd…## 3 3 Jayendra Lyne N/A Breakfa… 7 Low ## 4 4 Leon Rossini Anchovies Lunch o… 99999 Midd…## 5 5 Chidiegwu Dun… Pizza Breakfa… five HighVariable names
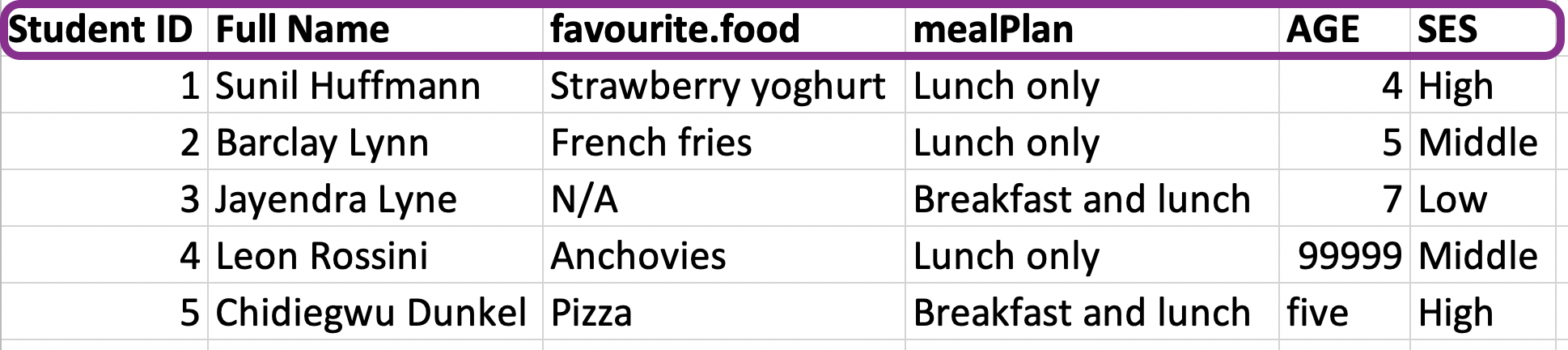
Variable names
fav_food <- read_excel("data/favourite-food.xlsx") %>% janitor::clean_names()fav_food## # A tibble: 5 × 6## student_id full_name favourite_food meal_plan age ses ## <dbl> <chr> <chr> <chr> <chr> <chr>## 1 1 Sunil Huffmann Strawberry yo… Lunch on… 4 High ## 2 2 Barclay Lynn French fries Lunch on… 5 Midd…## 3 3 Jayendra Lyne N/A Breakfas… 7 Low ## 4 4 Leon Rossini Anchovies Lunch on… 99999 Midd…## 5 5 Chidiegwu Dunk… Pizza Breakfas… five HighHandling NAs
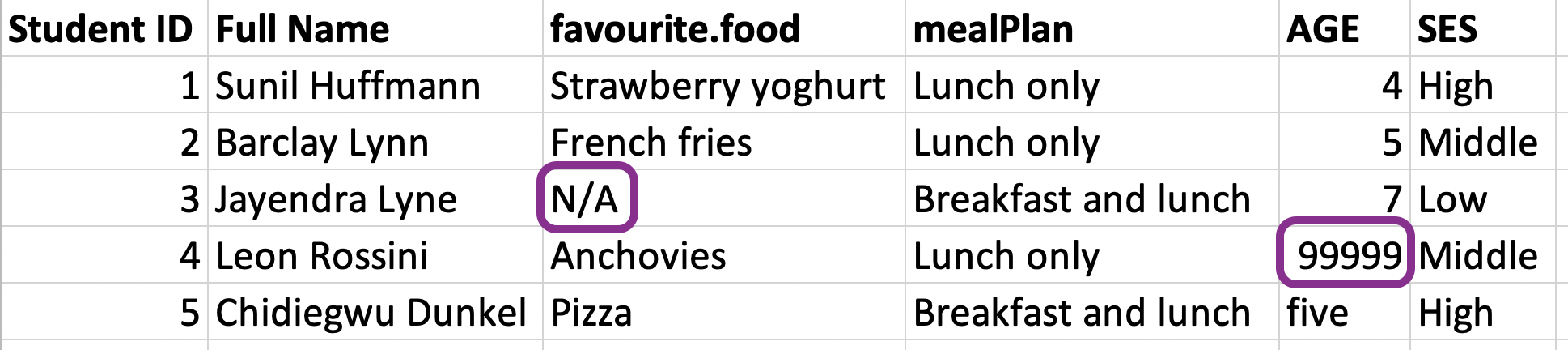
Handling NAs
fav_food <- read_excel("data/favourite-food.xlsx", na = c("N/A", "99999")) %>% janitor::clean_names()fav_food## # A tibble: 5 × 6## student_id full_name favourite_food meal_plan age ses ## <dbl> <chr> <chr> <chr> <chr> <chr>## 1 1 Sunil Huffmann Strawberry yo… Lunch on… 4 High ## 2 2 Barclay Lynn French fries Lunch on… 5 Midd…## 3 3 Jayendra Lyne <NA> Breakfas… 7 Low ## 4 4 Leon Rossini Anchovies Lunch on… <NA> Midd…## 5 5 Chidiegwu Dunk… Pizza Breakfas… five HighMake age numeric
fav_food <- fav_food %>% mutate( age = if_else(age == "five", "5", age), age = as.numeric(age) )glimpse(fav_food)## Rows: 5## Columns: 6## $ student_id <dbl> 1, 2, 3, 4, 5## $ full_name <chr> "Sunil Huffmann", "Barclay Lynn", "Jayen…## $ favourite_food <chr> "Strawberry yoghurt", "French fries", NA…## $ meal_plan <chr> "Lunch only", "Lunch only", "Breakfast a…## $ age <dbl> 4, 5, 7, NA, 5## $ ses <chr> "High", "Middle", "Low", "Middle", "High"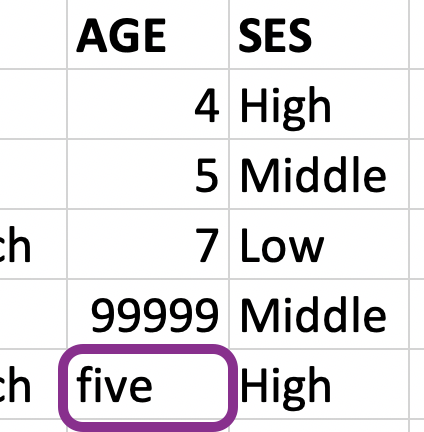
Socio-economic status
What order are the levels of ses listed in?
fav_food %>% count(ses)## # A tibble: 3 × 2## ses n## <chr> <int>## 1 High 2## 2 Low 1## 3 Middle 2