rvest
- The rvest package makes basic processing and manipulation of HTML data straight forward
- It's designed to work with pipelines built with
%>%

SelectorGadget
- Open source tool that eases CSS selector generation and discovery
- Easiest to use with the Chrome Extension
- Find out more on the SelectorGadget vignette
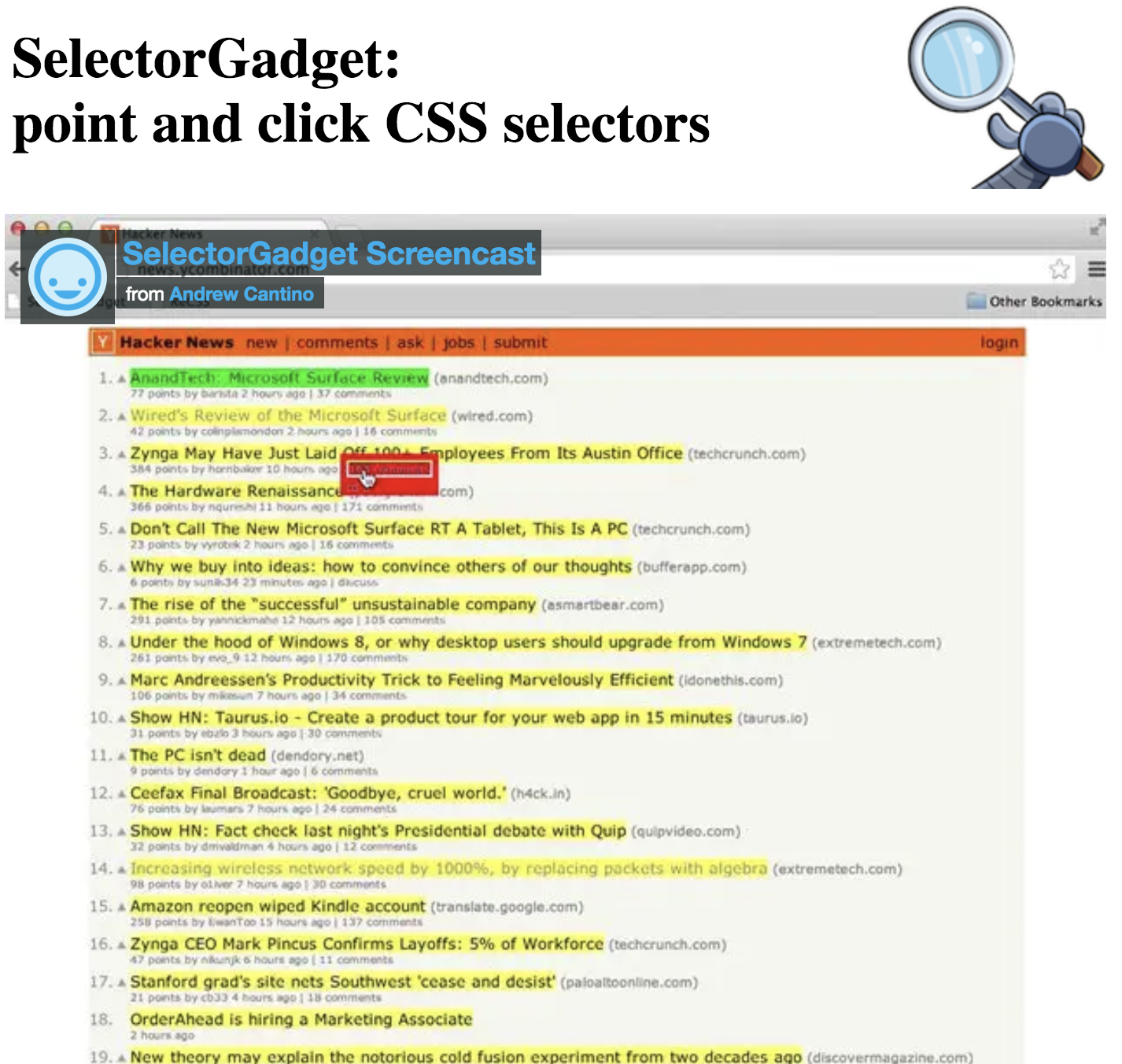
Using the SelectorGadget
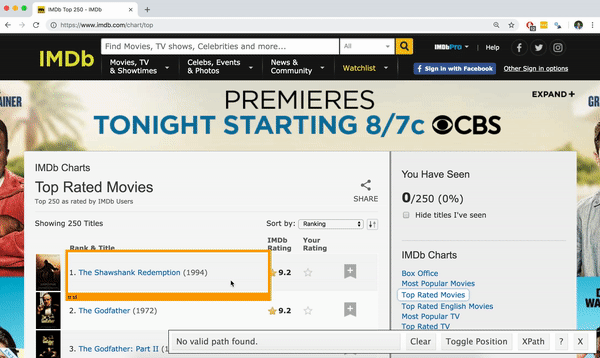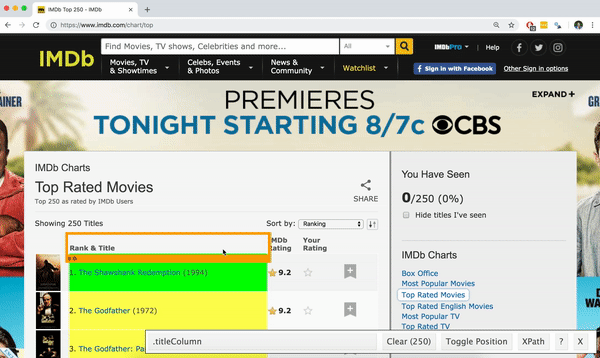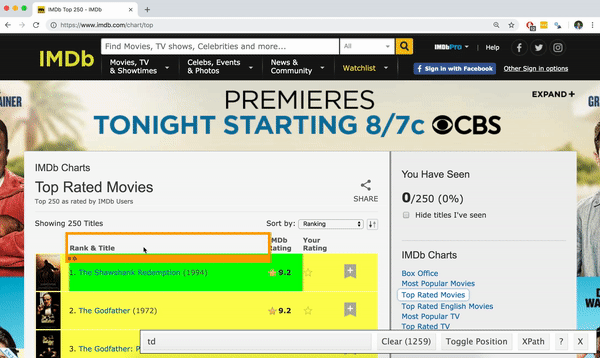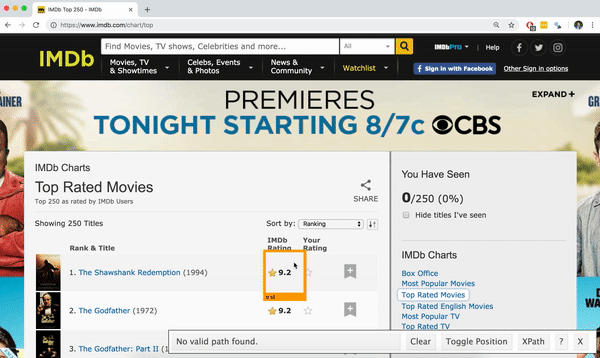
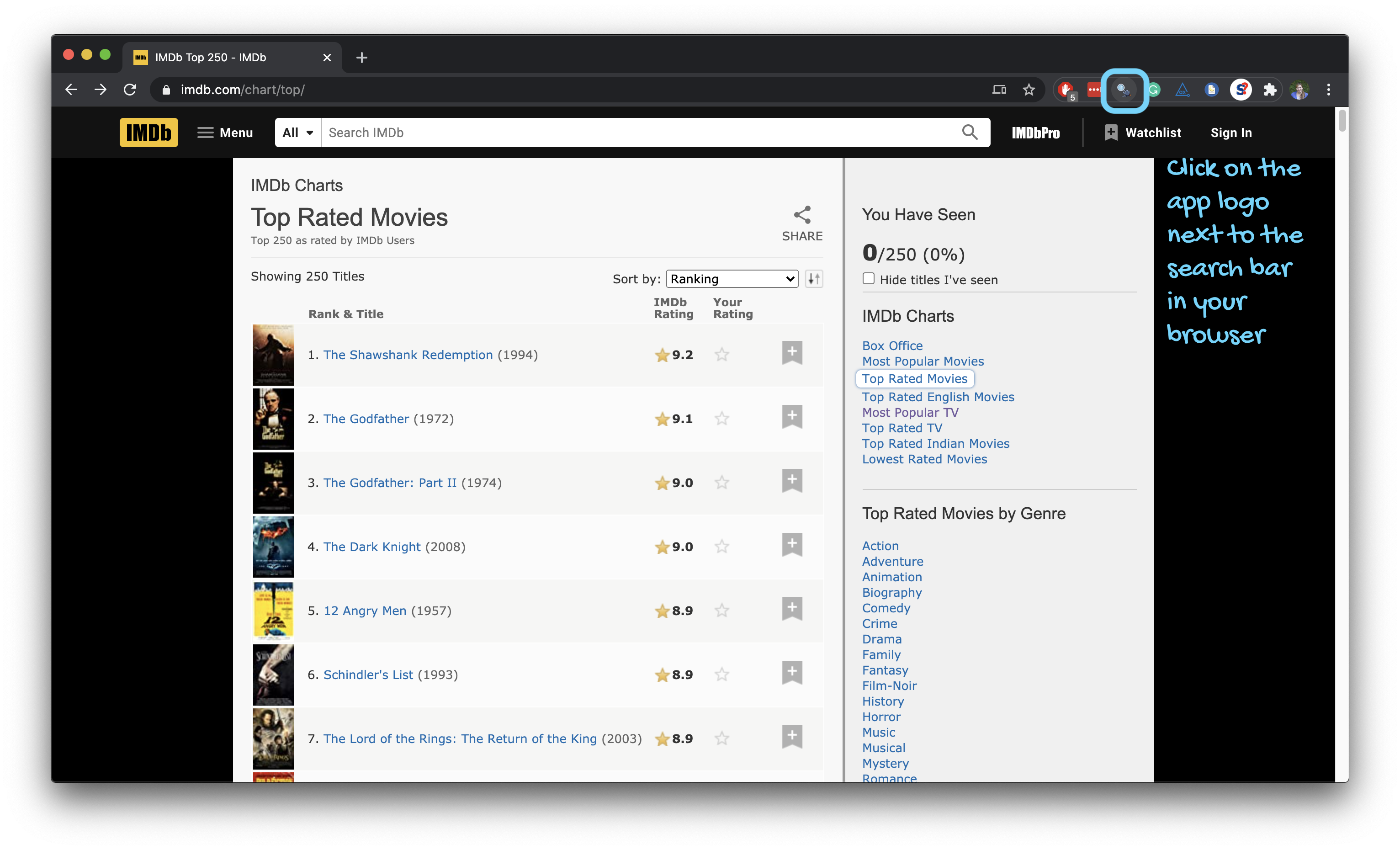
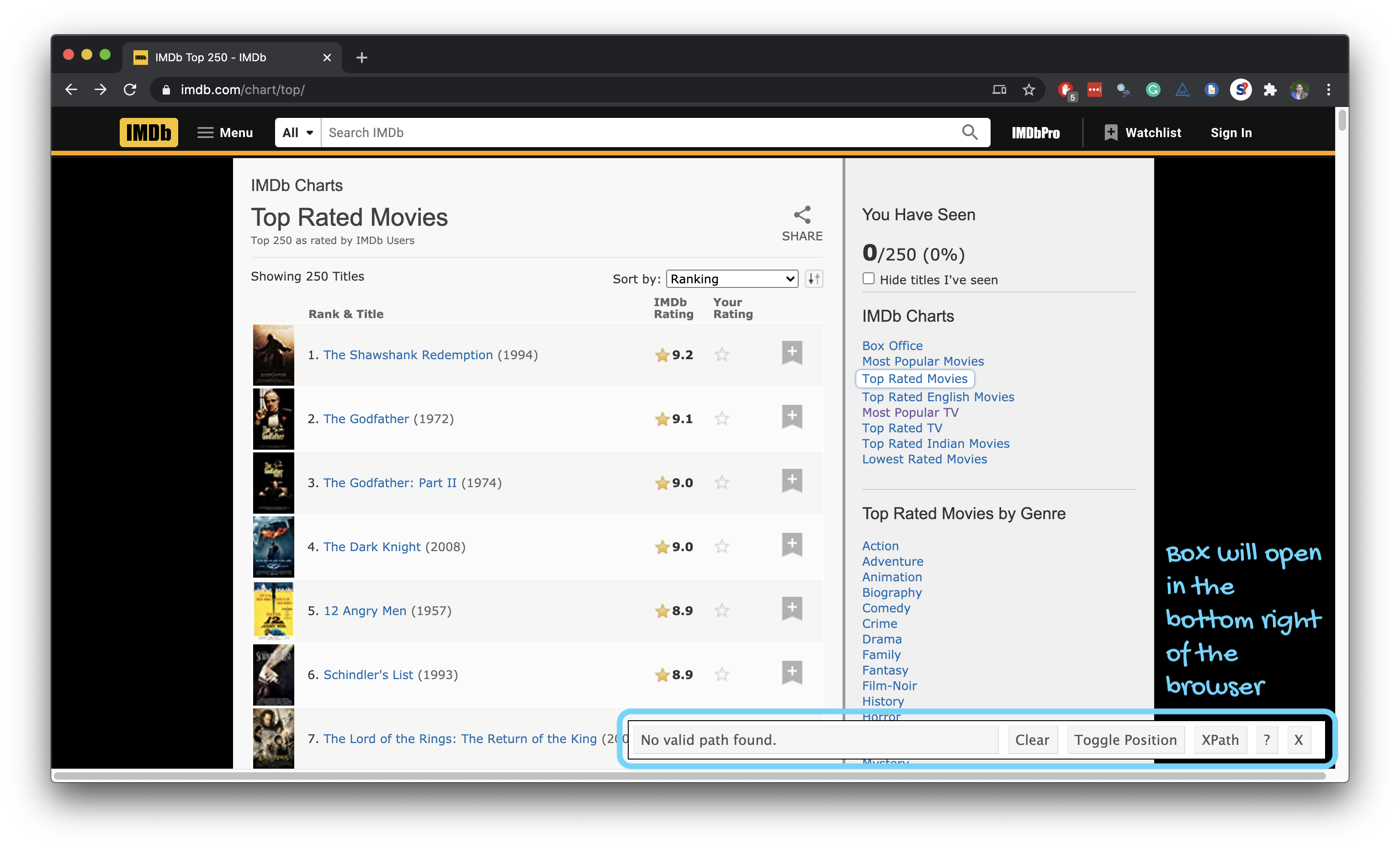
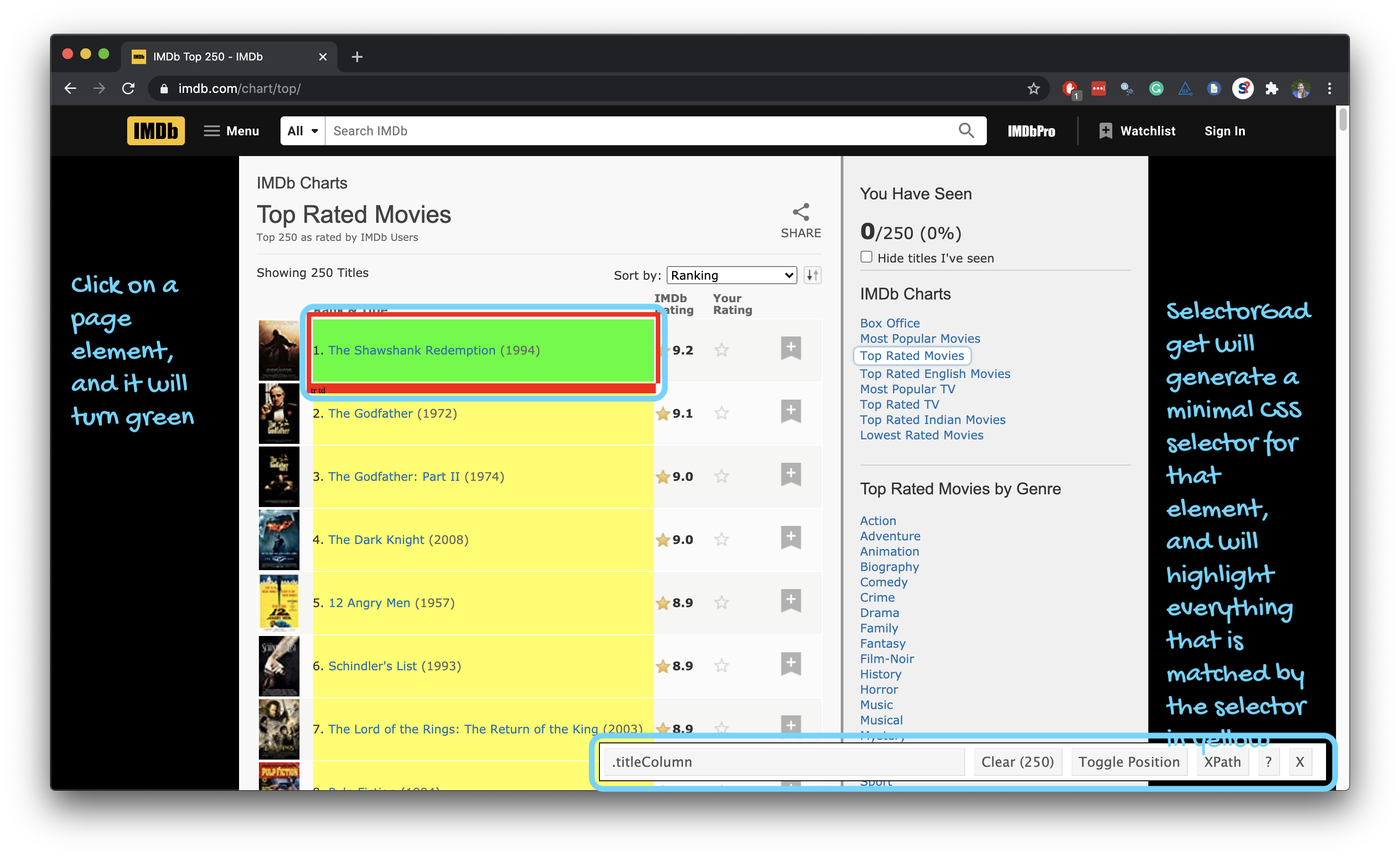
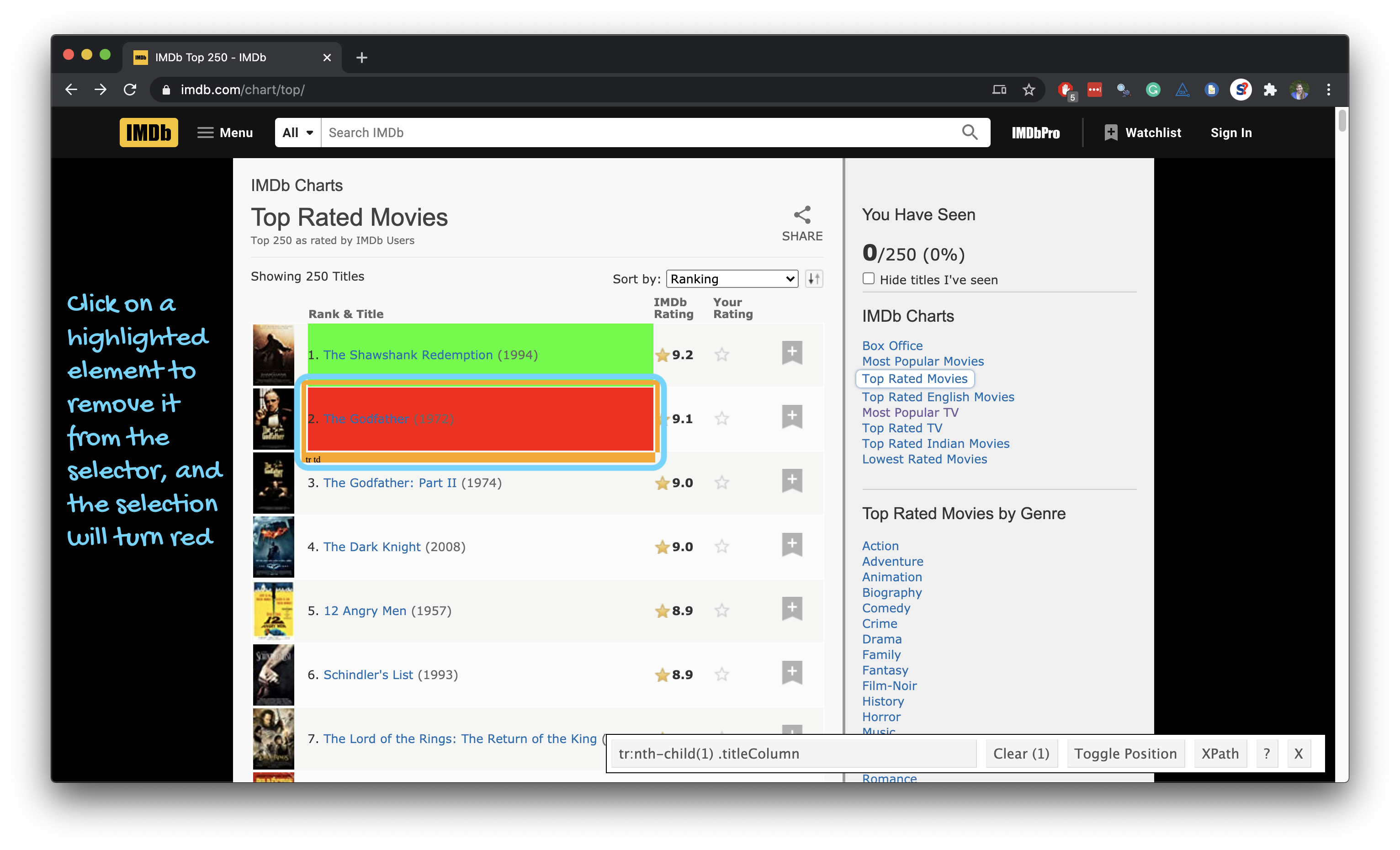
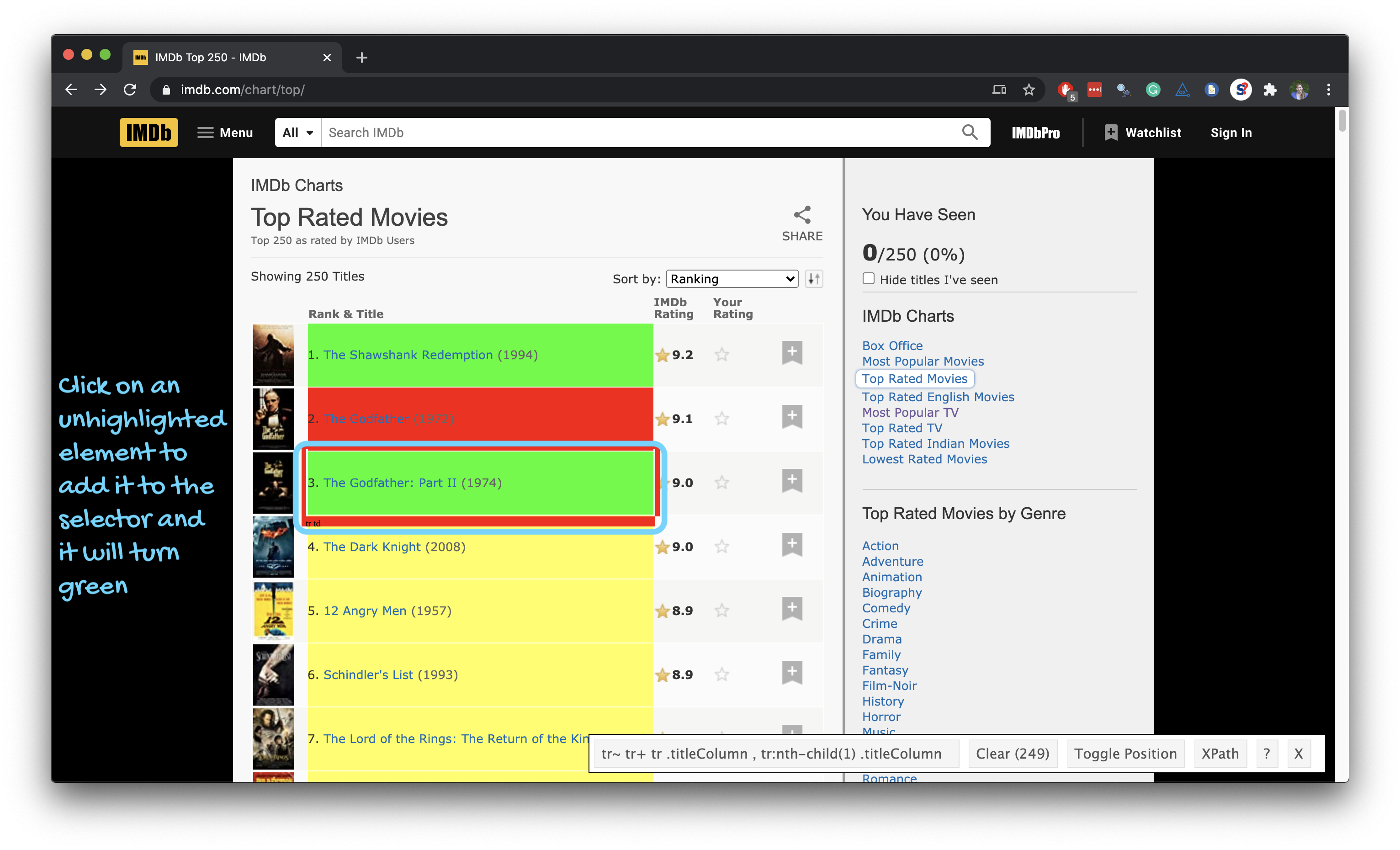
Using the SelectorGadget
Through this process of selection and rejection, SelectorGadget helps you come up with the appropriate CSS selector for your needs