Top 250 movies on IMDB
Take a look at the source code, look for the tag table tag:
http://www.imdb.com/chart/top

Plan
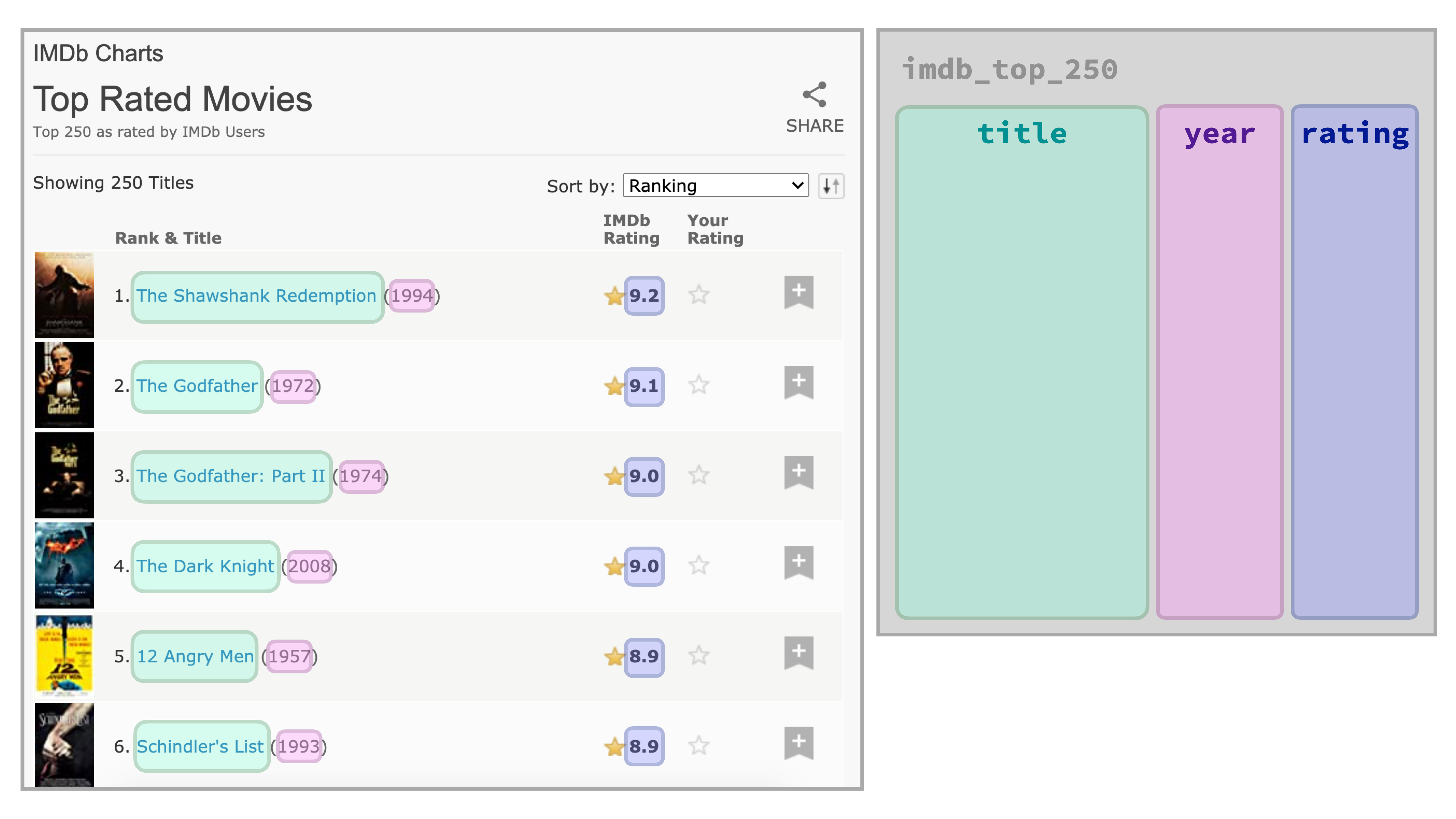
Scrape movie titles
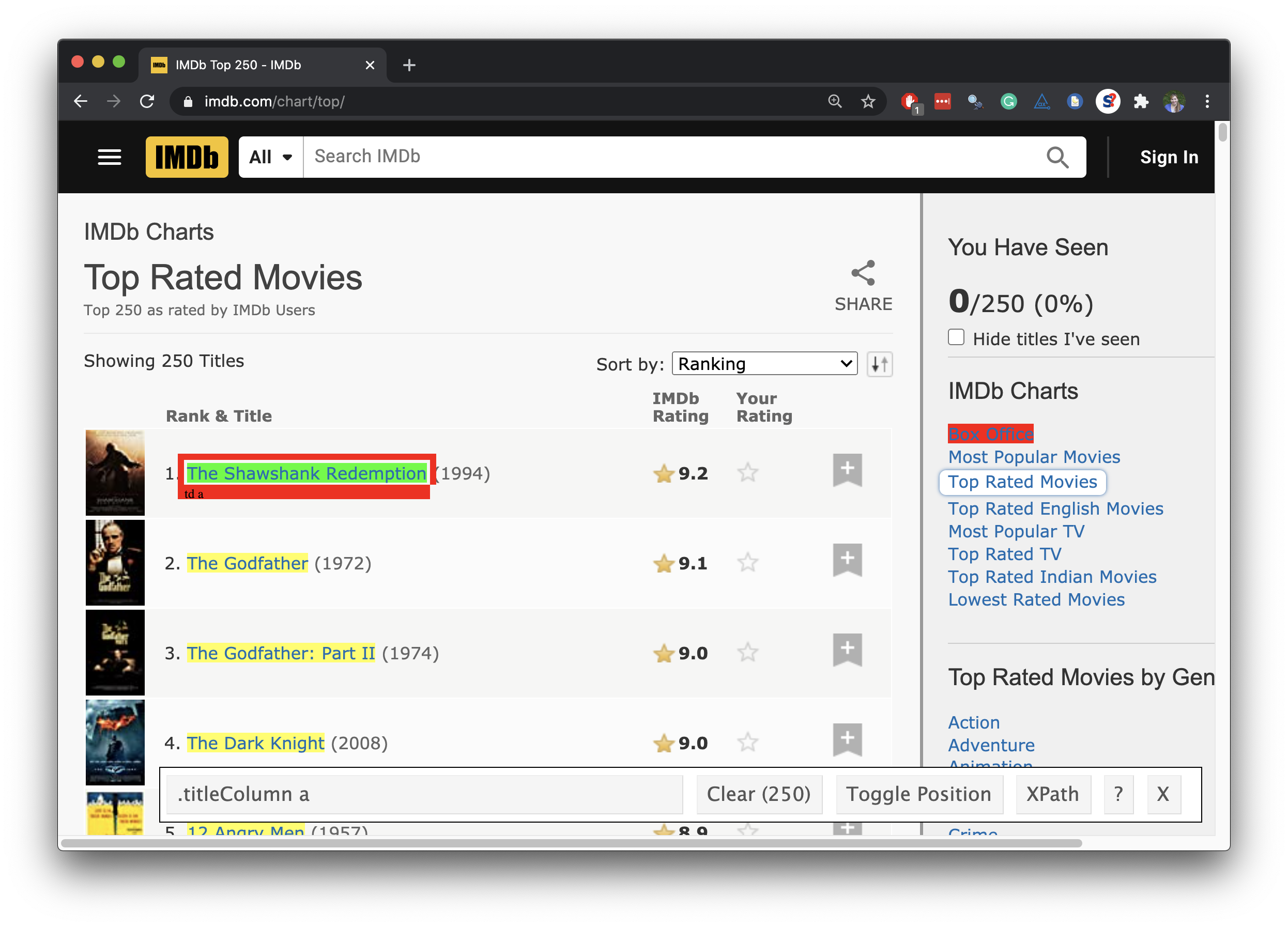
Scrape the nodes
page %>% html_nodes(".titleColumn a")## {xml_nodeset (250)}## [1] <a href="/title/tt0111161/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [2] <a href="/title/tt0068646/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [3] <a href="/title/tt0468569/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [4] <a href="/title/tt0071562/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [5] <a href="/title/tt0050083/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [6] <a href="/title/tt0108052/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [7] <a href="/title/tt0167260/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [8] <a href="/title/tt0110912/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [9] <a href="/title/tt0120737/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [10] <a href="/title/tt0060196/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [11] <a href="/title/tt0109830/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [12] <a href="/title/tt0137523/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [13] <a href="/title/tt1375666/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [14] <a href="/title/tt0167261/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [15] <a href="/title/tt0080684/?pf_rd_m=A2FGELUUNOQJNL&pf_ ...## [16] <a href="/title/tt0133093/?pf_rd_m=A2FGELUUNOQJNL&pf_ ......
Extract the text from the nodes
page %>% html_nodes(".titleColumn a") %>% html_text()## [1] "The Shawshank Redemption" ## [2] "The Godfather" ## [3] "The Dark Knight" ## [4] "The Godfather Part II" ## [5] "12 Angry Men" ## [6] "Schindler's List" ## [7] "The Lord of the Rings: The Return of the King" ## [8] "Pulp Fiction" ## [9] "The Lord of the Rings: The Fellowship of the Ring" ## [10] "The Good, the Bad and the Ugly" ## [11] "Forrest Gump" ## [12] "Fight Club" ## [13] "Inception" ## [14] "The Lord of the Rings: The Two Towers" ## [15] "Star Wars: Episode V - The Empire Strikes Back" ## [16] "The Matrix" ...
Save as titles
titles <- page %>% html_nodes(".titleColumn a") %>% html_text()titles## [1] "The Shawshank Redemption" ## [2] "The Godfather" ## [3] "The Dark Knight" ## [4] "The Godfather Part II" ## [5] "12 Angry Men" ## [6] "Schindler's List" ## [7] "The Lord of the Rings: The Return of the King" ## [8] "Pulp Fiction" ## [9] "The Lord of the Rings: The Fellowship of the Ring" ## [10] "The Good, the Bad and the Ugly" ## [11] "Forrest Gump" ## [12] "Fight Club" ## [13] "Inception" ## [14] "The Lord of the Rings: The Two Towers" ...
Scrape years movies were made in
Scrape the nodes
page %>% html_nodes(".secondaryInfo")## {xml_nodeset (250)}## [1] <span class="secondaryInfo">(1994)</span>## [2] <span class="secondaryInfo">(1972)</span>## [3] <span class="secondaryInfo">(2008)</span>## [4] <span class="secondaryInfo">(1974)</span>## [5] <span class="secondaryInfo">(1957)</span>## [6] <span class="secondaryInfo">(1993)</span>## [7] <span class="secondaryInfo">(2003)</span>## [8] <span class="secondaryInfo">(1994)</span>## [9] <span class="secondaryInfo">(2001)</span>## [10] <span class="secondaryInfo">(1966)</span>## [11] <span class="secondaryInfo">(1994)</span>## [12] <span class="secondaryInfo">(1999)</span>## [13] <span class="secondaryInfo">(2010)</span>## [14] <span class="secondaryInfo">(2002)</span>## [15] <span class="secondaryInfo">(1980)</span>## [16] <span class="secondaryInfo">(1999)</span>...
Extract the text from the nodes
page %>% html_nodes(".secondaryInfo") %>% html_text()## [1] "(1994)" "(1972)" "(2008)" "(1974)" "(1957)" "(1993)"## [7] "(2003)" "(1994)" "(2001)" "(1966)" "(1994)" "(1999)"## [13] "(2010)" "(2002)" "(1980)" "(1999)" "(1990)" "(1975)"## [19] "(1995)" "(1954)" "(1946)" "(1991)" "(2002)" "(1998)"## [25] "(1997)" "(1999)" "(2014)" "(1977)" "(1991)" "(1985)"## [31] "(2001)" "(1960)" "(2002)" "(1994)" "(2019)" "(1994)"## [37] "(2000)" "(1998)" "(1995)" "(2006)" "(2006)" "(1942)"## [43] "(2022)" "(2014)" "(2011)" "(1936)" "(1962)" "(1968)"## [49] "(1988)" "(1954)" "(1979)" "(1931)" "(1988)" "(2000)"## [55] "(1979)" "(1981)" "(2012)" "(2008)" "(2006)" "(1950)"## [61] "(1957)" "(1980)" "(1940)" "(1957)" "(2018)" "(1986)"## [67] "(1999)" "(1964)" "(2012)" "(2018)" "(2019)" "(2003)"## [73] "(1995)" "(1984)" "(1995)" "(2017)" "(1981)" "(2009)"## [79] "(1997)" "(2019)" "(1984)" "(1997)" "(2000)" "(2010)"## [85] "(2016)" "(1952)" "(2009)" "(1983)" "(1968)" "(2004)"## [91] "(1992)" "(1963)" "(2018)" "(1941)" "(1962)" "(2012)"...
stringr
- stringr provides a cohesive set of functions designed to make working with strings as easy as possible
Functions in stringr start with
str_*(), e.g.str_remove()to remove a pattern from a string
str_remove(string = "jello", pattern = "el")## [1] "jlo"str_replace()to replace a pattern with another
str_replace(string = "jello", pattern = "j", replacement = "h")## [1] "hello"

Save as years
years <- page %>% html_nodes(".secondaryInfo") %>% html_text() %>% str_remove("\\(") %>% # remove ( str_remove("\\)") %>% # remove ) as.numeric()years## [1] 1994 1972 2008 1974 1957 1993 2003 1994 2001 1966 1994 1999## [13] 2010 2002 1980 1999 1990 1975 1995 1954 1946 1991 2002 1998## [25] 1997 1999 2014 1977 1991 1985 2001 1960 2002 1994 2019 1994## [37] 2000 1998 1995 2006 2006 1942 2022 2014 2011 1936 1962 1968## [49] 1988 1954 1979 1931 1988 2000 1979 1981 2012 2008 2006 1950## [61] 1957 1980 1940 1957 2018 1986 1999 1964 2012 2018 2019 2003## [73] 1995 1984 1995 2017 1981 2009 1997 2019 1984 1997 2000 2010## [85] 2016 1952 2009 1983 1968 2004 1992 1963 2018 1941 1962 2012## [97] 1959 1931 1958 2001 1971 1985 1987 1944 1960 1983 1952 1973## [109] 1962 1976 1997 2009 1995 2020 1927 2011 2000 1988 2010 1989## [121] 1948 2021 2019 2007 2004 1965 2005 2016 1921 1959 2022 2020...
Scrape IMDB ratings
Scrape the nodes
page %>% html_nodes("strong")## {xml_nodeset (250)}## [1] <strong title="9.2 based on 2,598,663 user ratings">9.2</ ...## [2] <strong title="9.2 based on 1,794,051 user ratings">9.2</ ...## [3] <strong title="9.0 based on 2,569,907 user ratings">9.0</ ...## [4] <strong title="9.0 based on 1,236,627 user ratings">9.0</ ...## [5] <strong title="8.9 based on 767,804 user ratings">8.9</st ...## [6] <strong title="8.9 based on 1,321,819 user ratings">8.9</ ...## [7] <strong title="8.9 based on 1,784,964 user ratings">8.9</ ...## [8] <strong title="8.9 based on 1,992,218 user ratings">8.9</ ...## [9] <strong title="8.8 based on 1,806,022 user ratings">8.8</ ...## [10] <strong title="8.8 based on 745,449 user ratings">8.8</st ...## [11] <strong title="8.8 based on 2,007,365 user ratings">8.8</ ...## [12] <strong title="8.8 based on 2,046,596 user ratings">8.8</ ...## [13] <strong title="8.7 based on 2,280,290 user ratings">8.7</ ...## [14] <strong title="8.7 based on 1,612,066 user ratings">8.7</ ...## [15] <strong title="8.7 based on 1,257,435 user ratings">8.7</ ...## [16] <strong title="8.7 based on 1,866,072 user ratings">8.7</ ......
Extract the text from the nodes
page %>% html_nodes("strong") %>% html_text()## [1] "9.2" "9.2" "9.0" "9.0" "8.9" "8.9" "8.9" "8.9" "8.8" "8.8"## [11] "8.8" "8.8" "8.7" "8.7" "8.7" "8.7" "8.7" "8.6" "8.6" "8.6"## [21] "8.6" "8.6" "8.6" "8.6" "8.6" "8.6" "8.6" "8.6" "8.5" "8.5"## [31] "8.5" "8.5" "8.5" "8.5" "8.5" "8.5" "8.5" "8.5" "8.5" "8.5"## [41] "8.5" "8.5" "8.5" "8.5" "8.5" "8.4" "8.4" "8.4" "8.4" "8.4"## [51] "8.4" "8.4" "8.4" "8.4" "8.4" "8.4" "8.4" "8.4" "8.4" "8.4"## [61] "8.4" "8.4" "8.4" "8.4" "8.4" "8.3" "8.3" "8.3" "8.3" "8.3"## [71] "8.3" "8.3" "8.3" "8.3" "8.3" "8.3" "8.3" "8.3" "8.3" "8.3"## [81] "8.3" "8.3" "8.3" "8.3" "8.3" "8.3" "8.3" "8.3" "8.3" "8.3"## [91] "8.3" "8.3" "8.3" "8.3" "8.3" "8.3" "8.3" "8.3" "8.2" "8.2"## [101] "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2"## [111] "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2"## [121] "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2"## [131] "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2" "8.2"## [141] "8.2" "8.2" "8.2" "8.2" "8.2" "8.1" "8.1" "8.1" "8.1" "8.1"## [151] "8.1" "8.1" "8.1" "8.1" "8.1" "8.1" "8.1" "8.1" "8.1" "8.1"...
Convert to numeric
page %>% html_nodes("strong") %>% html_text() %>% as.numeric()## [1] 9.2 9.2 9.0 9.0 8.9 8.9 8.9 8.9 8.8 8.8 8.8 8.8 8.7 8.7 8.7## [16] 8.7 8.7 8.6 8.6 8.6 8.6 8.6 8.6 8.6 8.6 8.6 8.6 8.6 8.5 8.5## [31] 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5## [46] 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4## [61] 8.4 8.4 8.4 8.4 8.4 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3## [76] 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3## [91] 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.2 8.2 8.2 8.2 8.2 8.2 8.2## [106] 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2## [121] 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2## [136] 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.1 8.1 8.1 8.1 8.1## [151] 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1## [166] 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1## [181] 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1## [196] 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1## [211] 8.1 8.0 8.0 8.0 8.0 8.0 8.0 8.0 8.0 8.0 8.0 8.0 8.0 8.0 8.0...
Save as ratings
ratings <- page %>% html_nodes("strong") %>% html_text() %>% as.numeric()ratings## [1] 9.2 9.2 9.0 9.0 8.9 8.9 8.9 8.9 8.8 8.8 8.8 8.8 8.7 8.7 8.7## [16] 8.7 8.7 8.6 8.6 8.6 8.6 8.6 8.6 8.6 8.6 8.6 8.6 8.6 8.5 8.5## [31] 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5 8.5## [46] 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4 8.4## [61] 8.4 8.4 8.4 8.4 8.4 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3## [76] 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3## [91] 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.3 8.2 8.2 8.2 8.2 8.2 8.2 8.2## [106] 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2## [121] 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2## [136] 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.2 8.1 8.1 8.1 8.1 8.1## [151] 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1## [166] 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1 8.1...
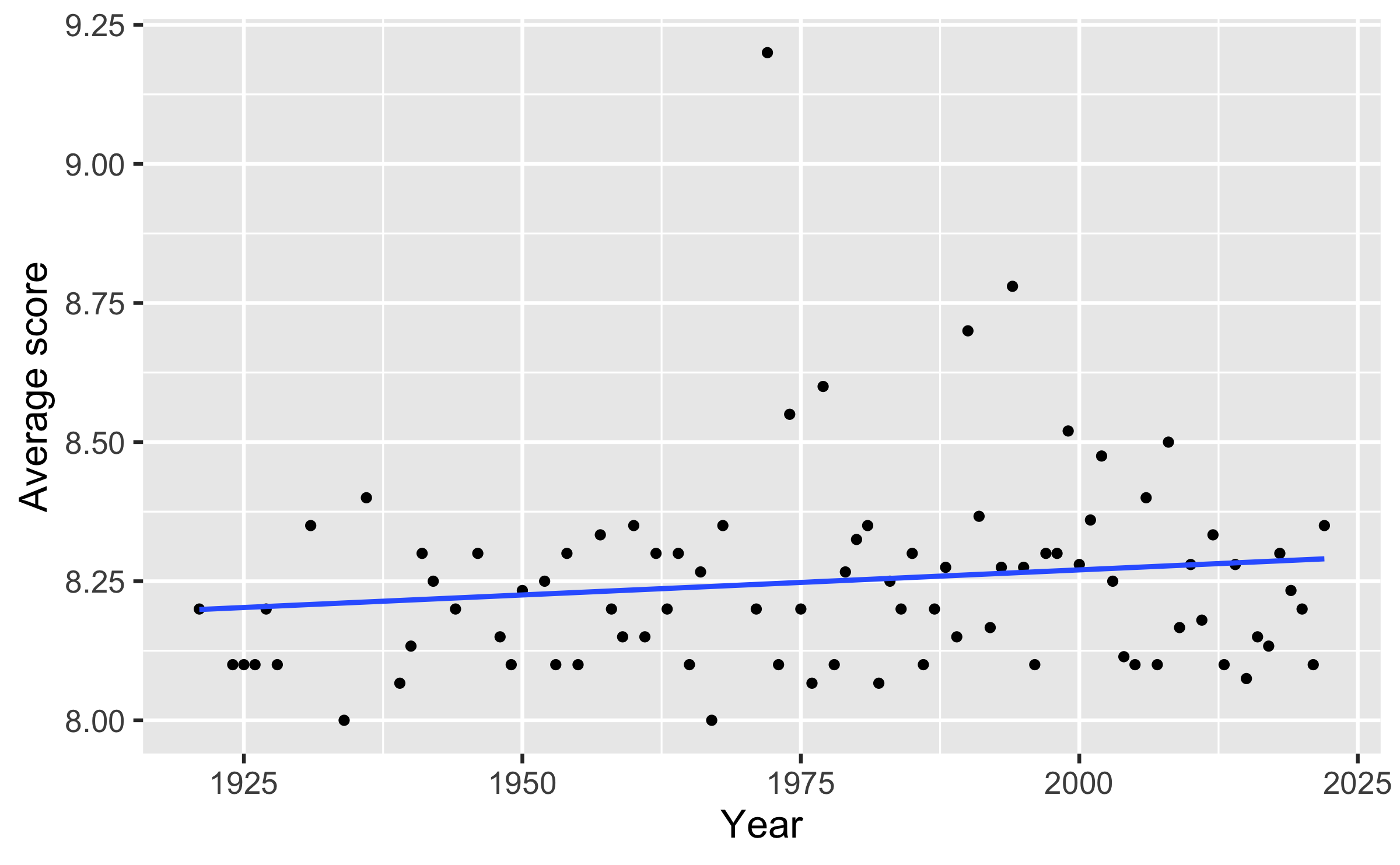
Visualize the average yearly rating for movies that made it on the top 250 list over time.