"Can you?" vs "Should you?"
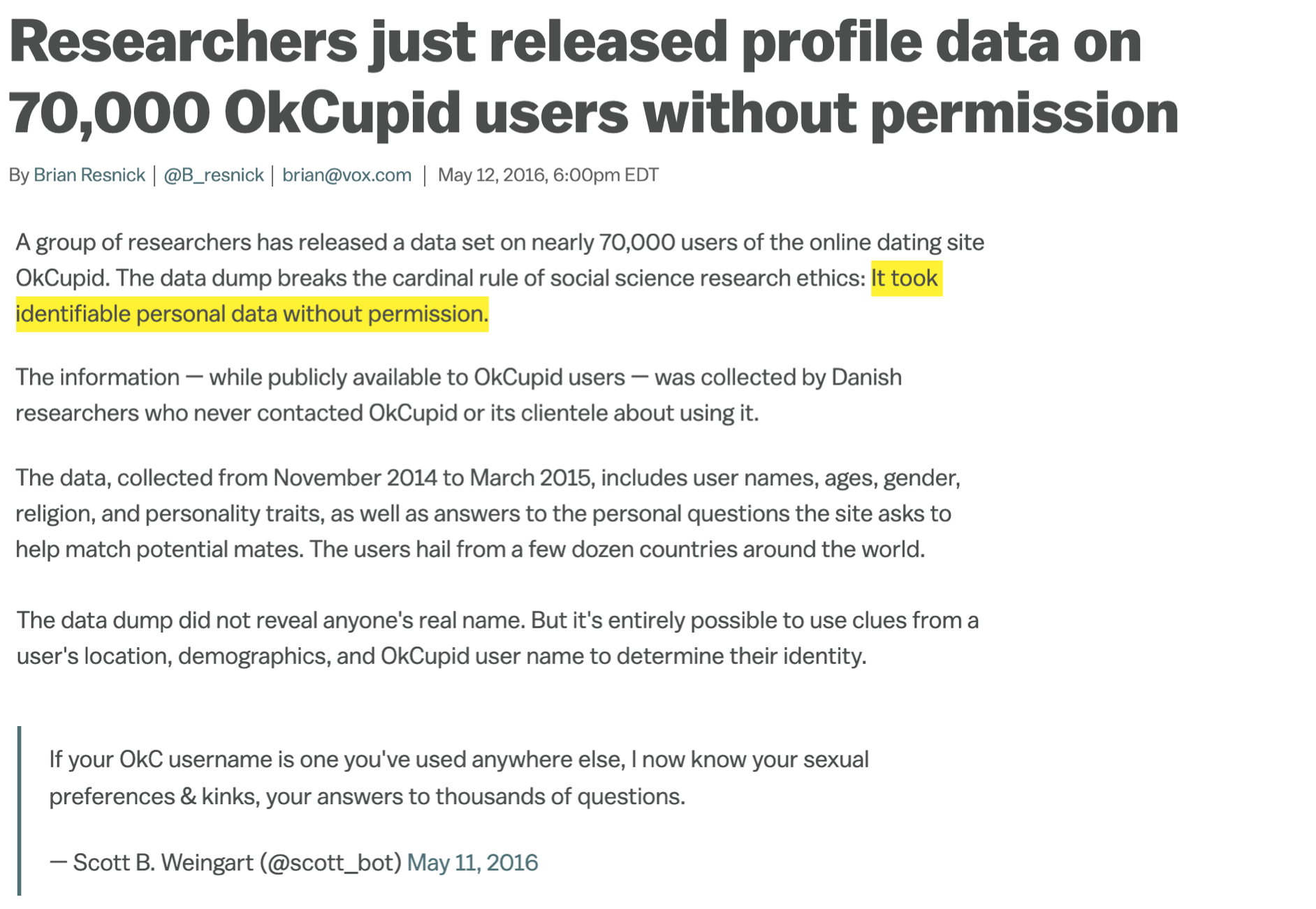
Source: Brian Resnick, Researchers just released profile data on 70,000 OkCupid users without permission, Vox.
"Can you?" vs "Should you?"
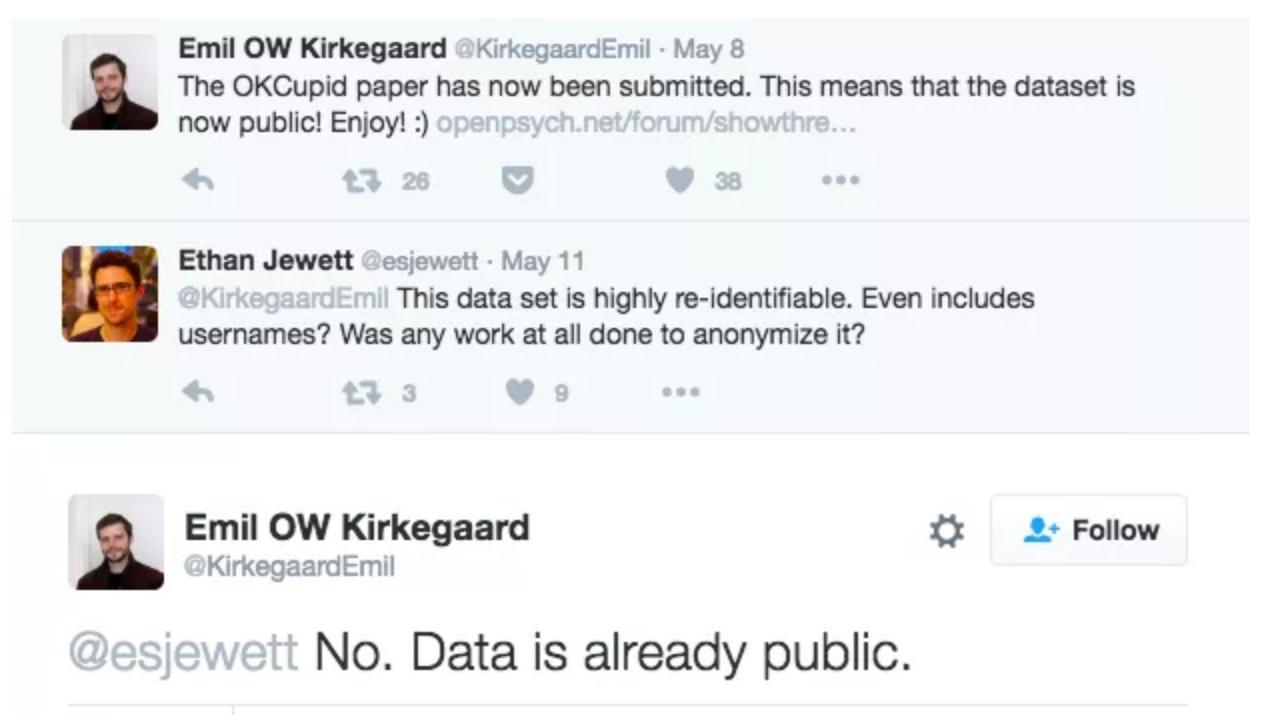
Unreliable formatting at the source
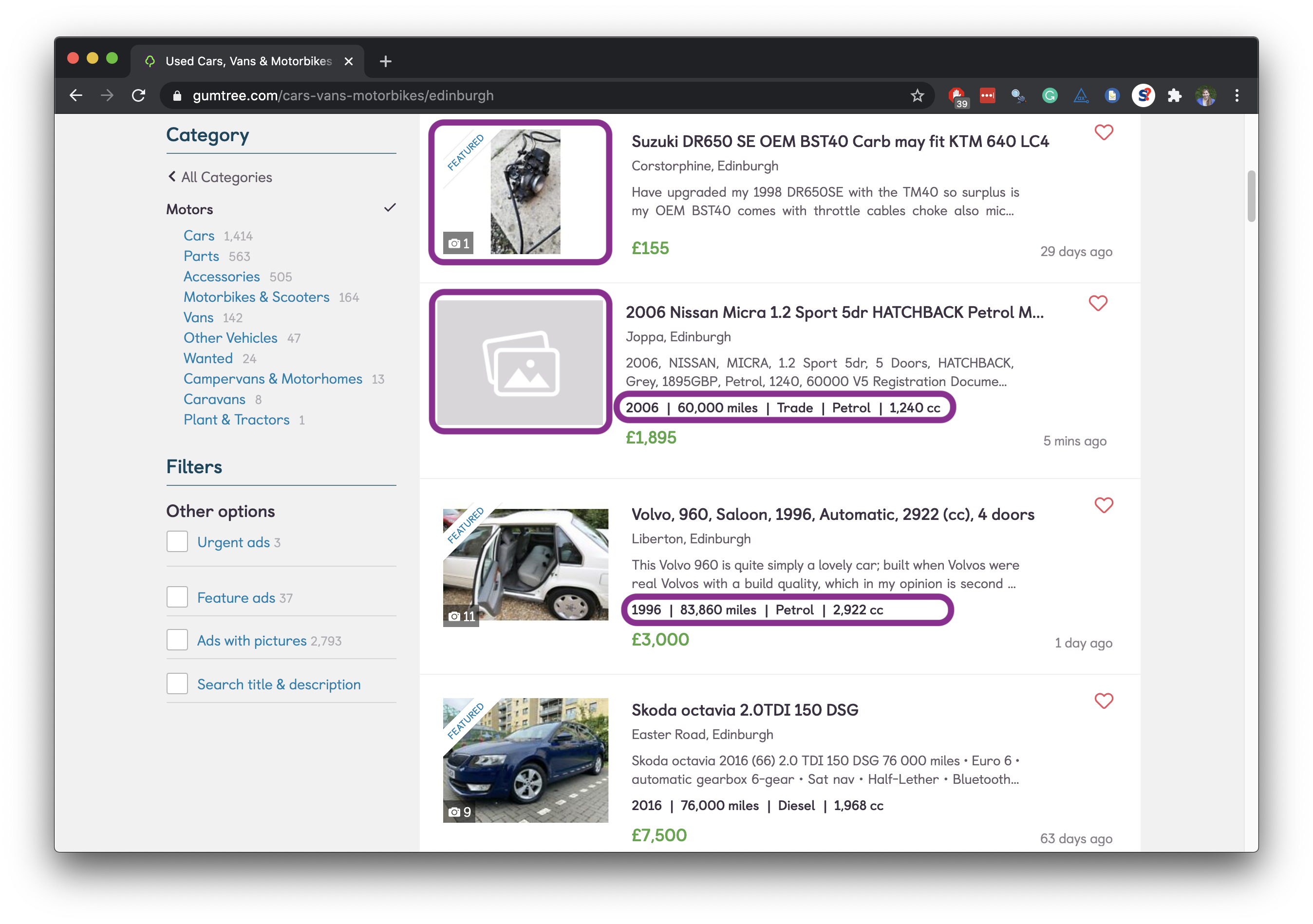
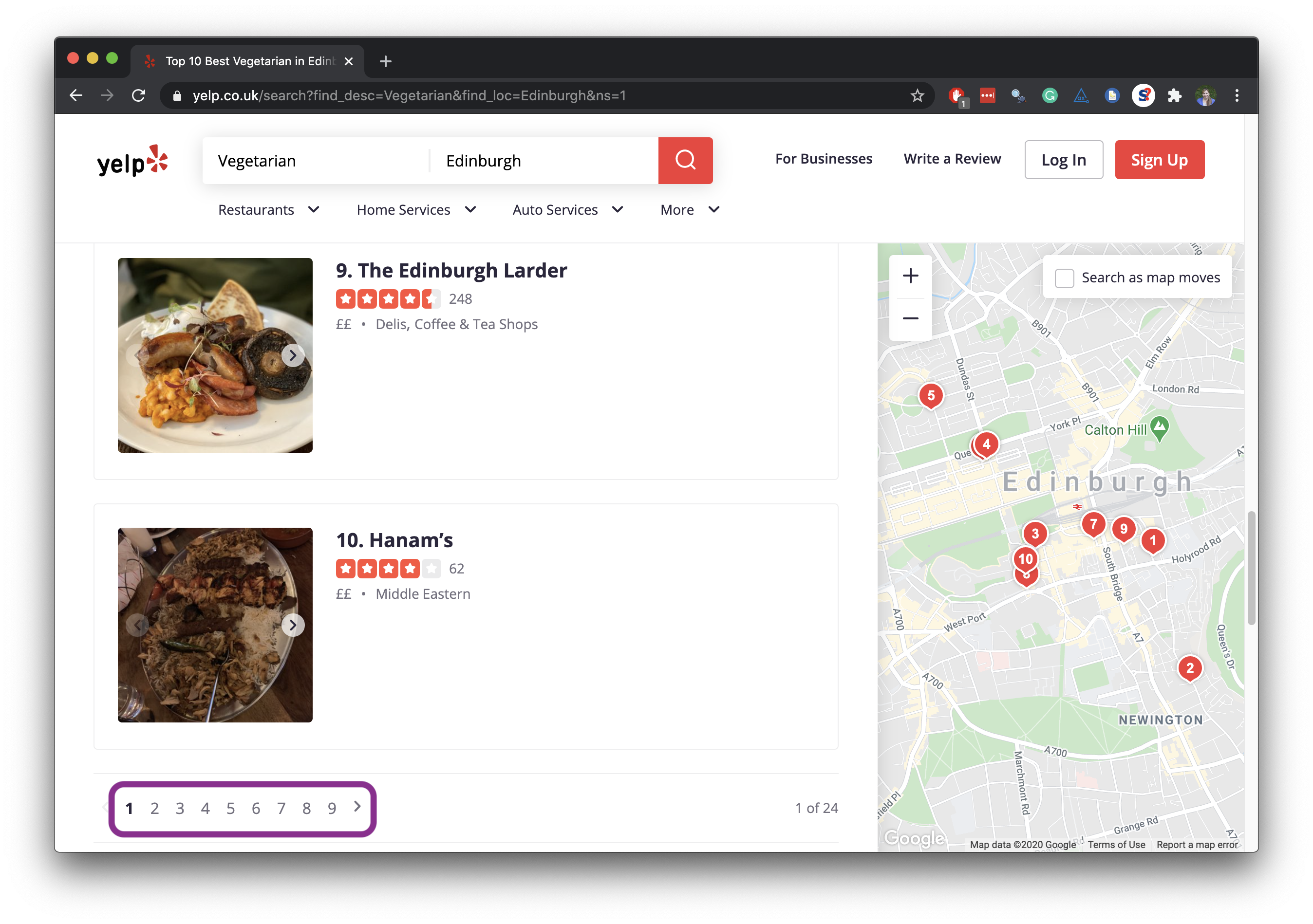
Data broken into many pages
Source: Brian Resnick, Researchers just released profile data on 70,000 OkCupid users without permission, Vox.
Keyboard shortcuts
| ↑, ←, Pg Up, k | Go to previous slide |
| ↓, →, Pg Dn, Space, j | Go to next slide |
| Home | Go to first slide |
| End | Go to last slide |
| Number + Return | Go to specific slide |
| b / m / f | Toggle blackout / mirrored / fullscreen mode |
| c | Clone slideshow |
| p | Toggle presenter mode |
| t | Restart the presentation timer |
| ?, h | Toggle this help |
| Esc | Back to slideshow |