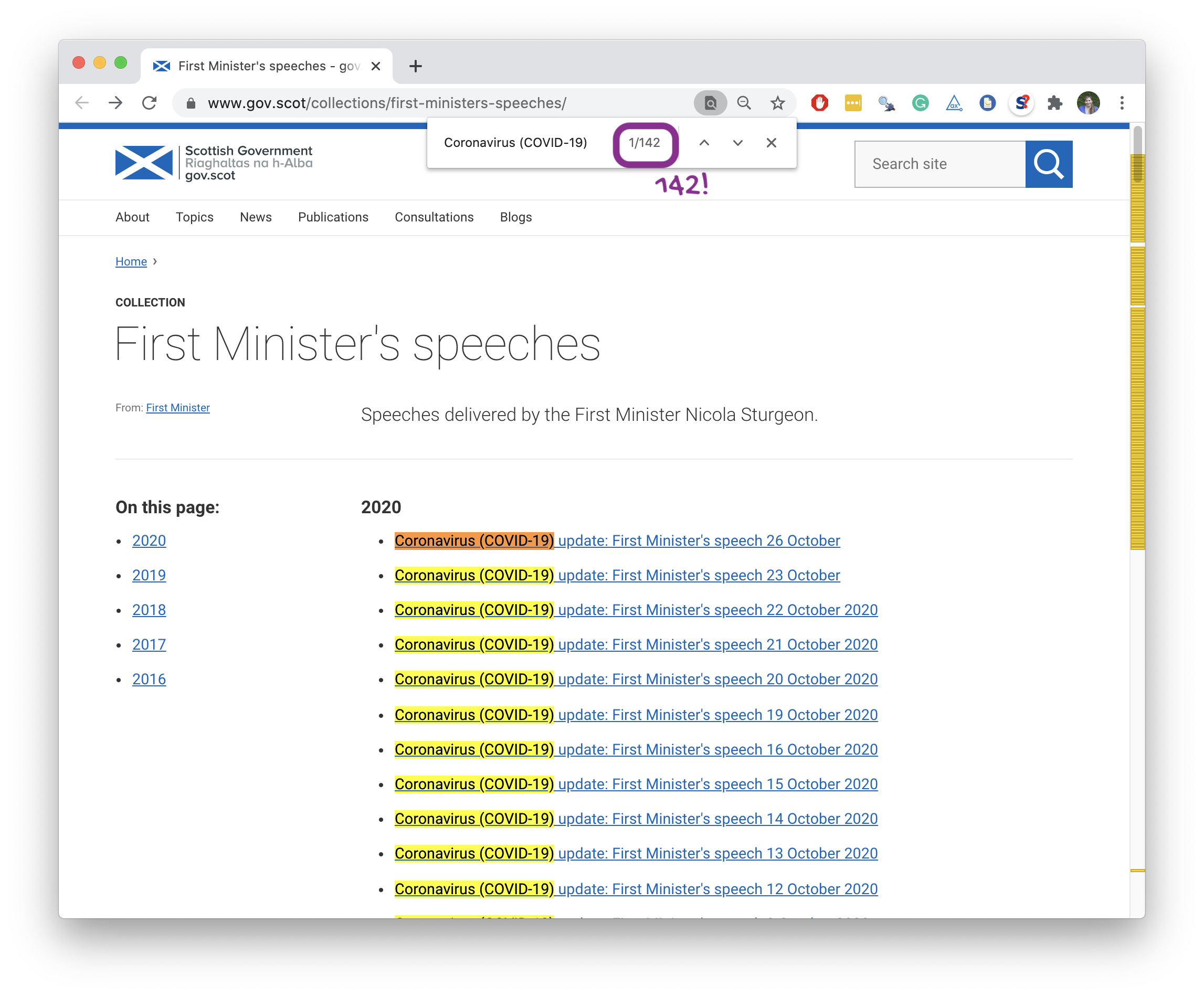
🏁 Start with
Read page for 26 Oct speech
url <- "https://www.gov.scot/publications/coronavirus-covid-19-update-first-ministers-speech-26-october/"speech_page <- read_html(url)speech_page## {html_document}## <html dir="ltr" lang="en">## [1] <head>\n<meta http-equiv="Content-Type" content="text/html ...## [2] <body class="fontawesome site-header__container">\n\n\n\n\ ...
Extract title
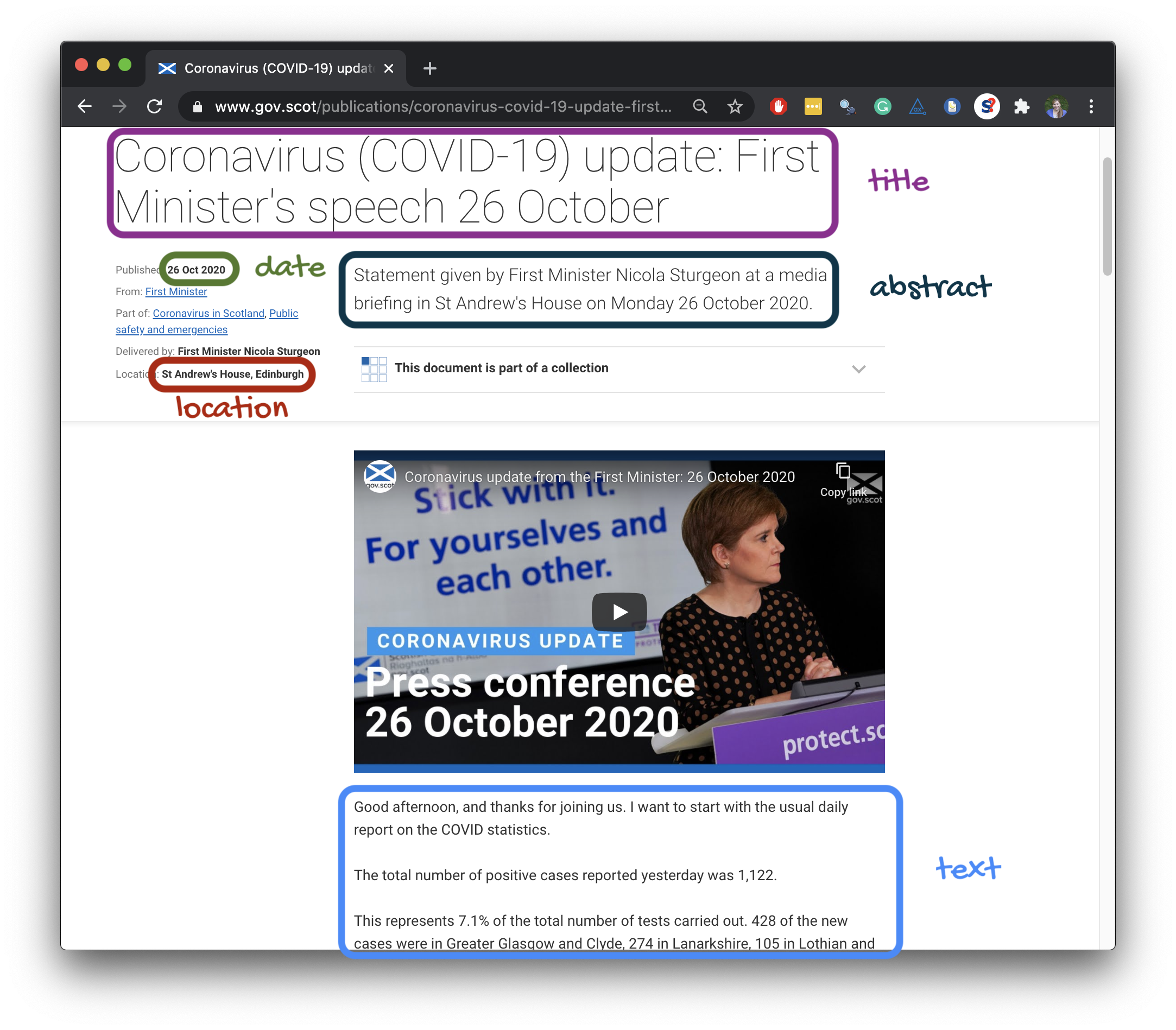
title <- speech_page %>% html_node(".article-header__title") %>% html_text()title## [1] "Coronavirus (COVID-19) update: First Minister's speech 26 October"
Extract date
library(lubridate)speech_page %>% html_node(".content-data__list:nth-child(1) strong") %>% html_text()## [1] "26 Oct 2020"date <- speech_page %>% html_node(".content-data__list:nth-child(1) strong") %>% html_text() %>% dmy()date## [1] "2020-10-26"
Extract location
location <- speech_page %>% html_node(".content-data__list+ .content-data__list strong") %>% html_text()location## [1] "St Andrew's House, Edinburgh"
Extract abstract
abstract <- speech_page %>% html_node(".leader--first-para p") %>% html_text()abstract## [1] "Statement given by First Minister Nicola Sturgeon at a media briefing in St Andrew's House on Monday 26 October 2020."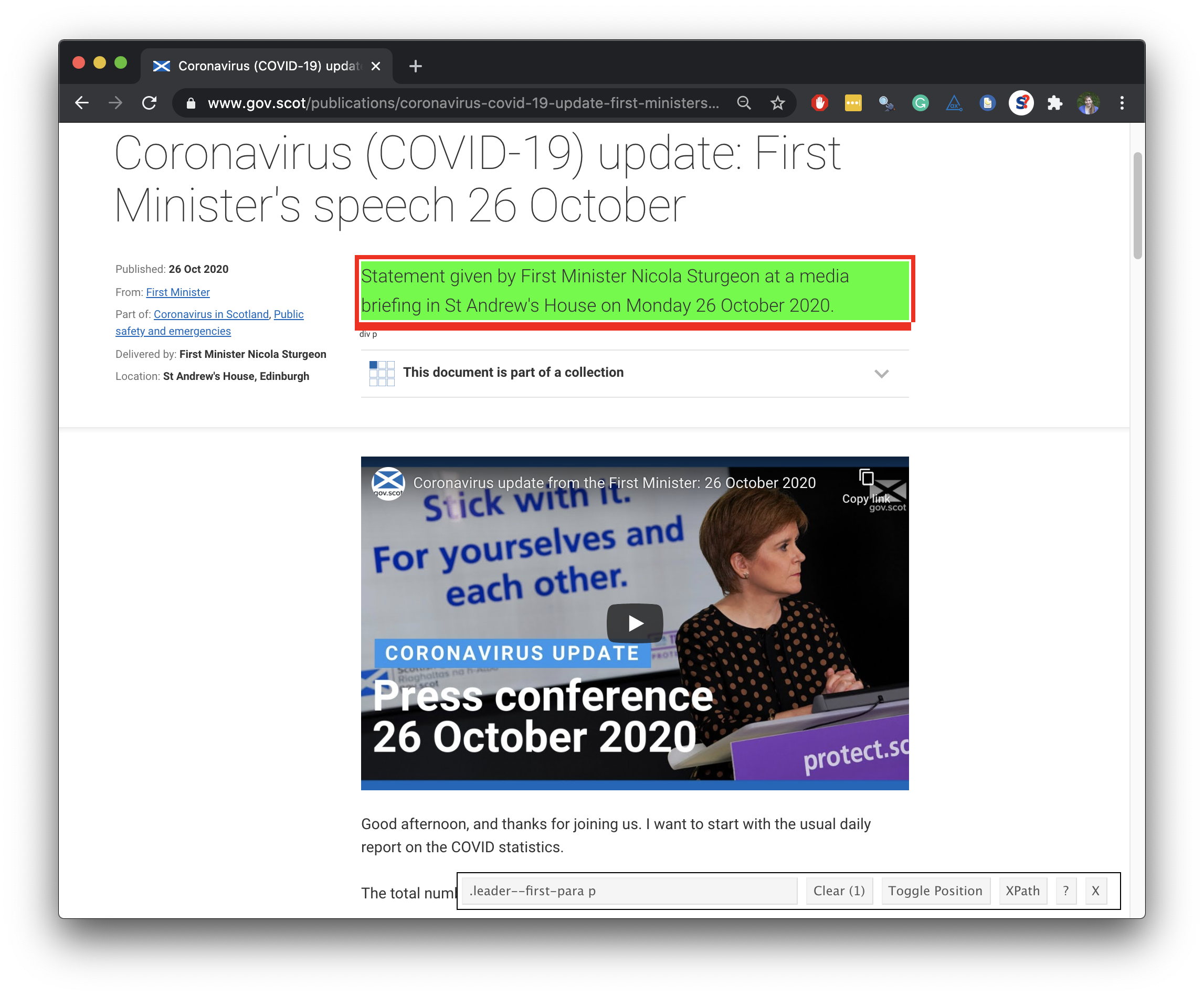
Extract text
text <- speech_page %>% html_nodes("#preamble p") %>% html_text() %>% list()text## [[1]]## [1] "\nGood afternoon, and thanks for joining us. I want to start with the usual daily report on the COVID statistics." ## [2] "The total number of positive cases reported yesterday was 1,122." ## [3] "This represents 7.1% of the total number of tests carried out. 428 of the new cases were in Greater Glasgow and Clyde, 274 in Lanarkshire, 105 in Lothian and 97 in Ayrshire and Arran. " ## [4] "The remaining cases were spread across the mainland health board regions. " ## [5] "The total number of confirmed cases is now 57,874." ## [6] "I can also confirm that 1,152 people are in hospital – that is an increase of 36 from yesterday" ## [7] "90 people are in intensive care, which is four more than yesterday." ## [8] "And I regret to say that in the last 24 hours, one further death has been registered of a patient who first tested positive over the previous 28 days. It is important though to remember that registration offices tend not to be open as normal over the weekend so the Sunday and Monday figures are often lower." ## [9] "We also reported 11 deaths on Saturday, and one yesterday. So since the last briefing on Friday, 13 additional deaths have been registered. That takes the total number of deaths, under this measurement, to 2,701." ## [10] "That reminds us again of how dangerous this virus can be and I want to send my condolences to everyone who has lost someone." ...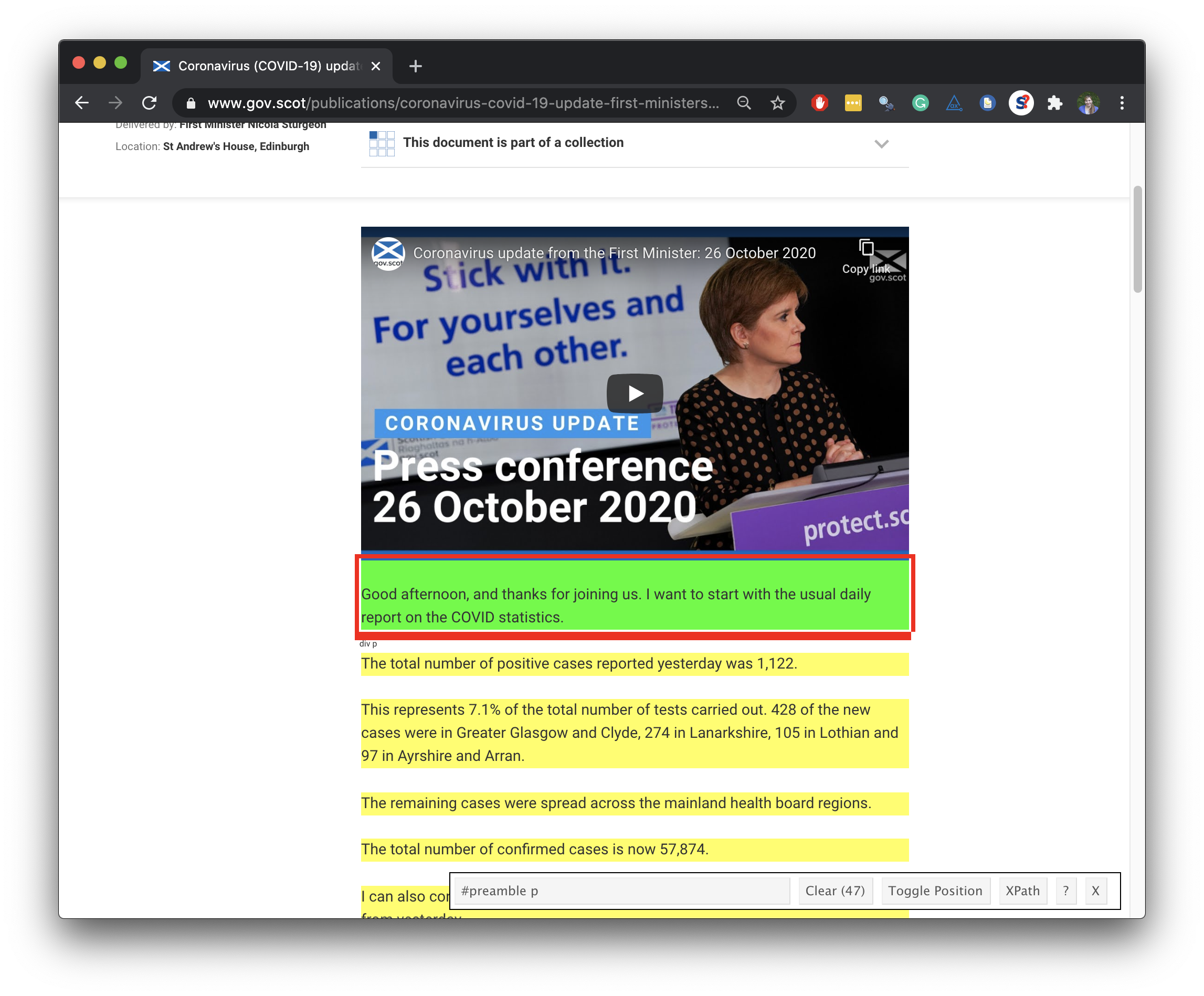
Put it all in a data frame
oct_26_speech <- tibble( title = title, date = date, location = location, abstract = abstract, text = text, url = url)oct_26_speech## # A tibble: 1 × 6## title date location abstract text url ## <chr> <date> <chr> <chr> <lis> <chr>## 1 Coronavirus (COVID-19… 2020-10-26 St Andr… Stateme… <chr> http…
Put it all in a data frame
oct_23_speech <- tibble( title = title, date = date, location = location, abstract = abstract, text = text, url = url)oct_23_speech## # A tibble: 1 × 6## title date location abstract text url ## <chr> <date> <chr> <chr> <lis> <chr>## 1 Coronavirus (COVID-19… 2020-10-23 St Andr… Stateme… <chr> http…
When should you write a function?

When should you write a function?
When you’ve copied and pasted a block of code more than twice.
How many times will we need to copy and paste the code we developed to scrape data on all of First Minister's COVID-19 speeches?