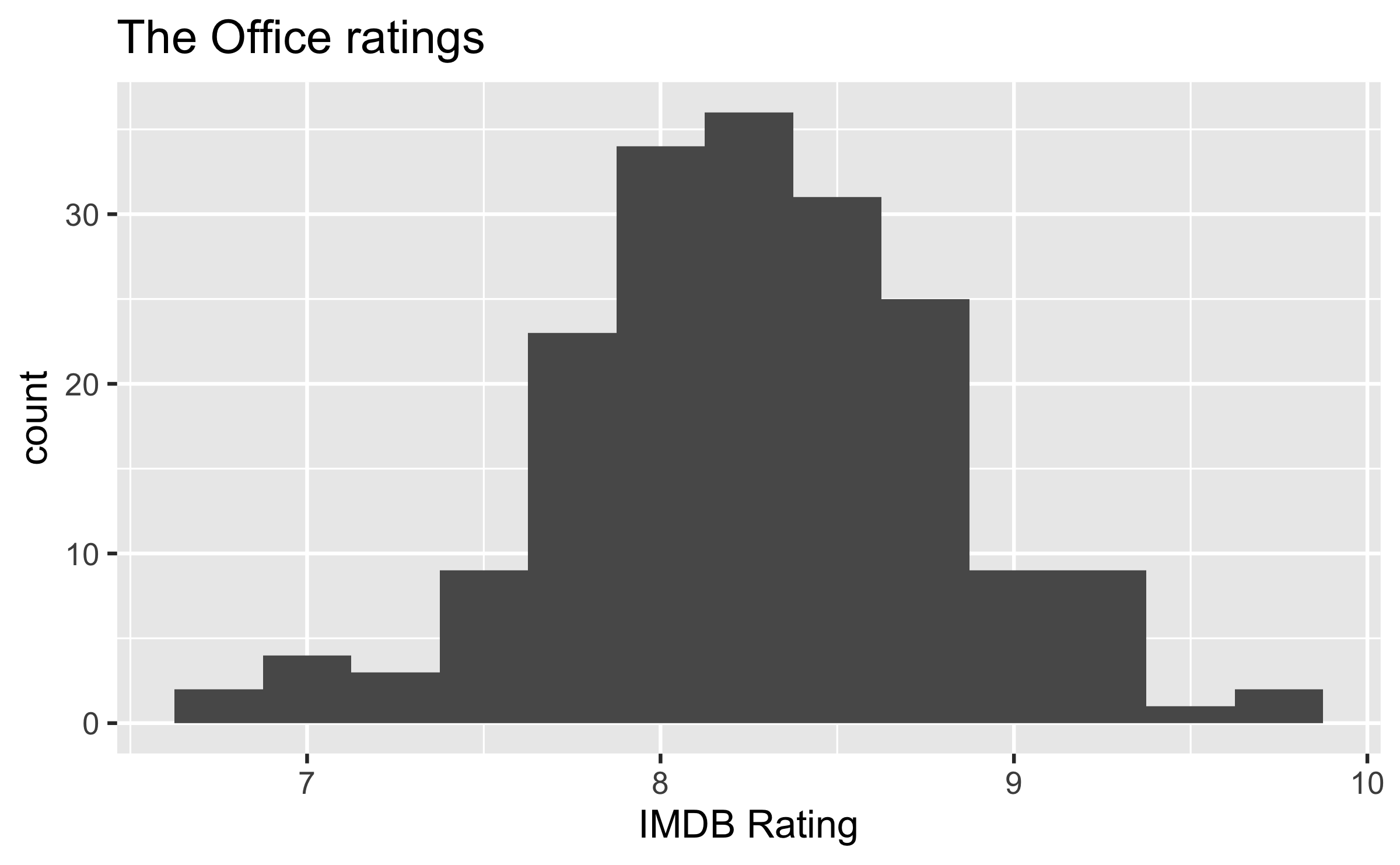
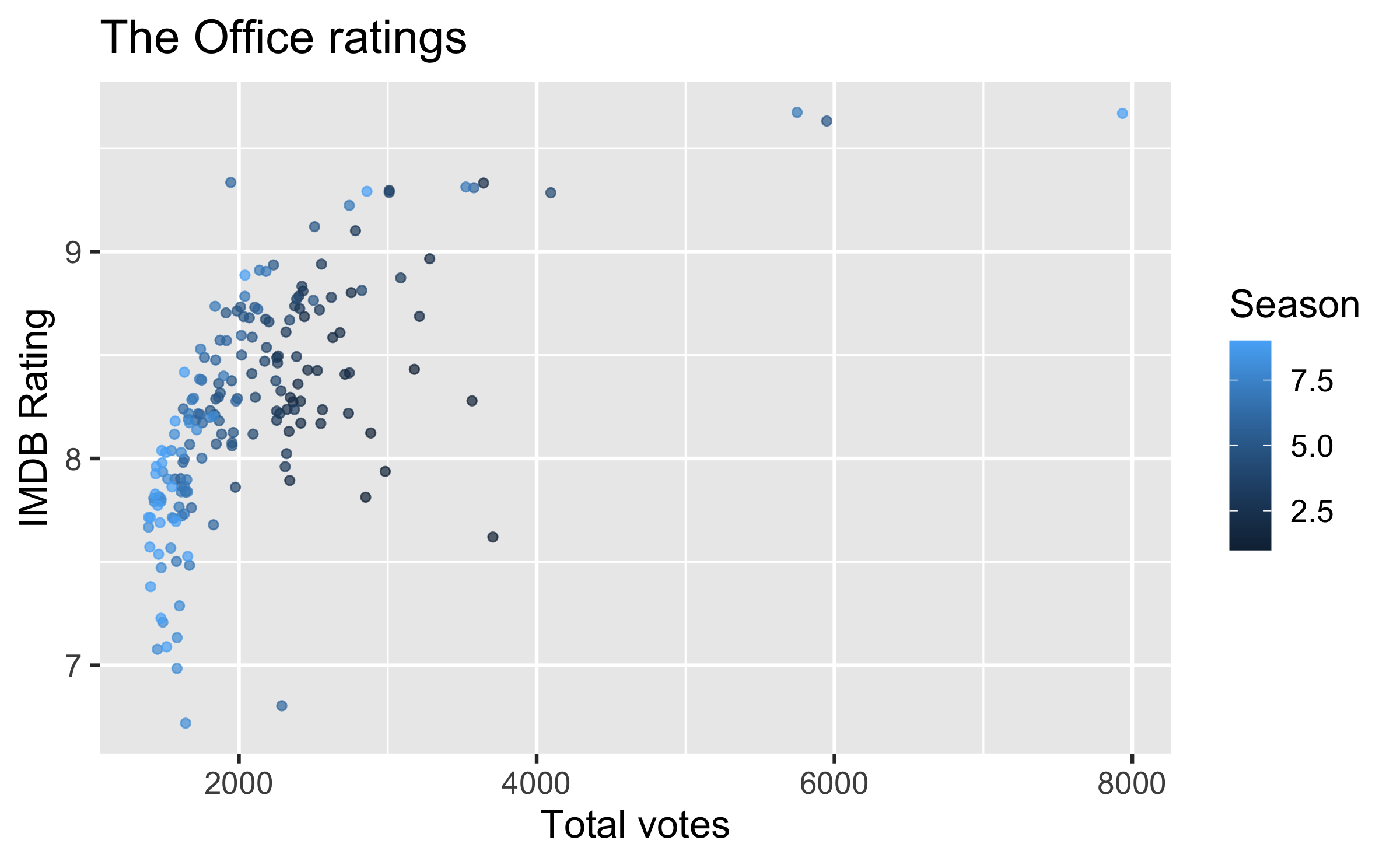
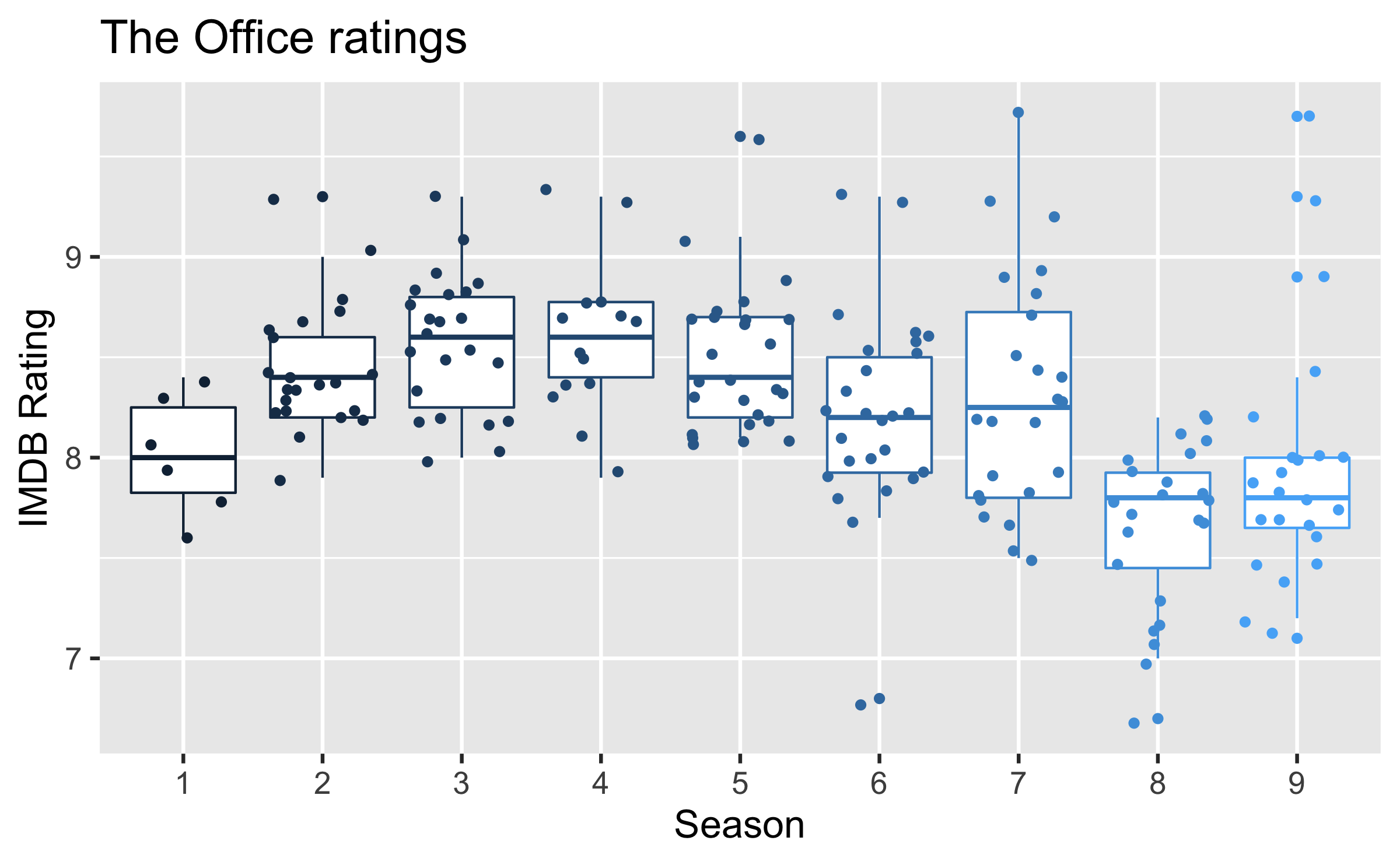
Outliers
ggplot(office_ratings, aes(x = total_votes, y = imdb_rating)) + geom_jitter() + gghighlight(total_votes > 4000, label_key = title) + labs( title = "The Office ratings", x = "Total votes", y = "IMDB Rating" )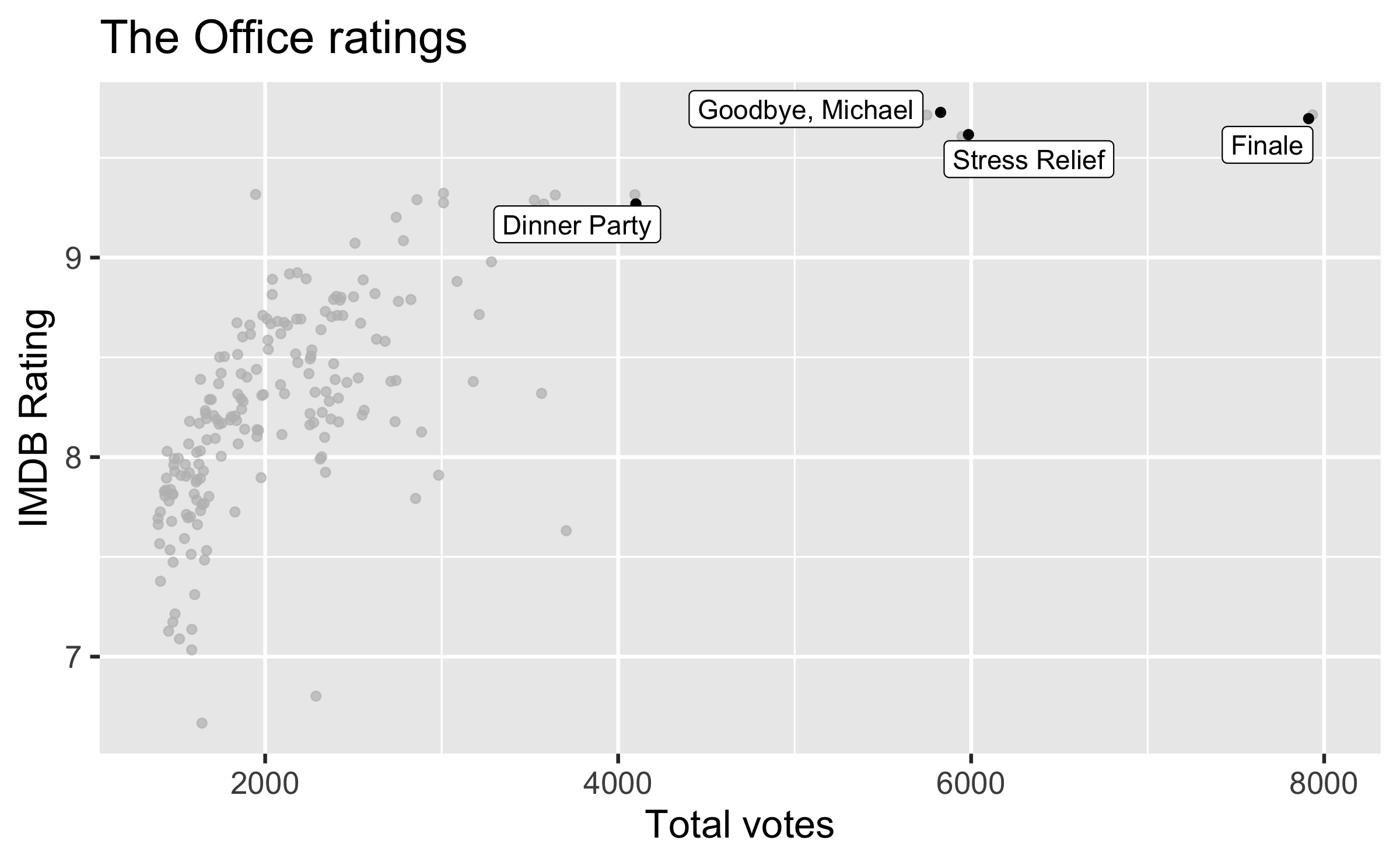
If you like the Dinner Party episode, I highly recommend this "oral history" of the episode published on Rolling Stone magazine.
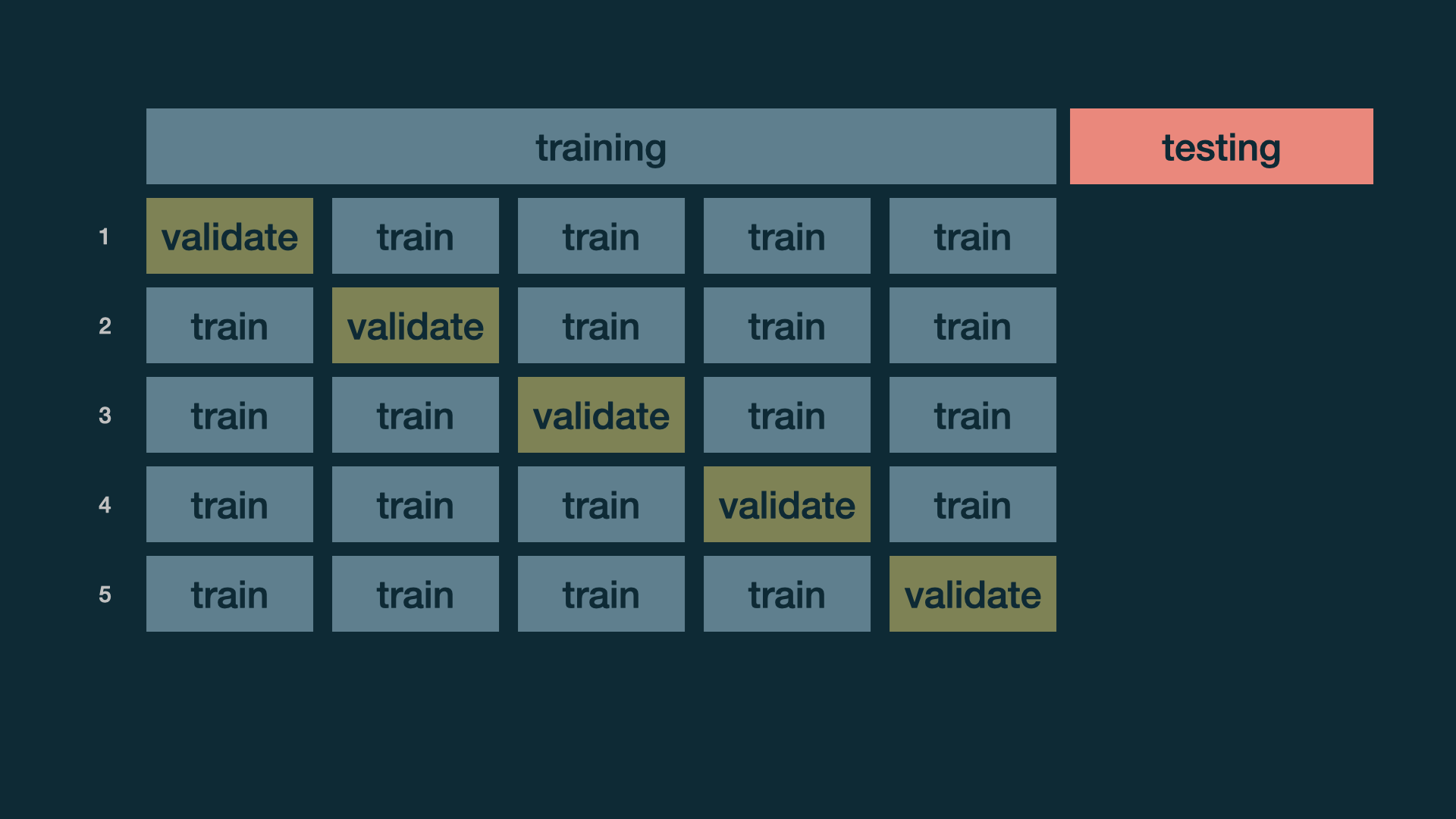
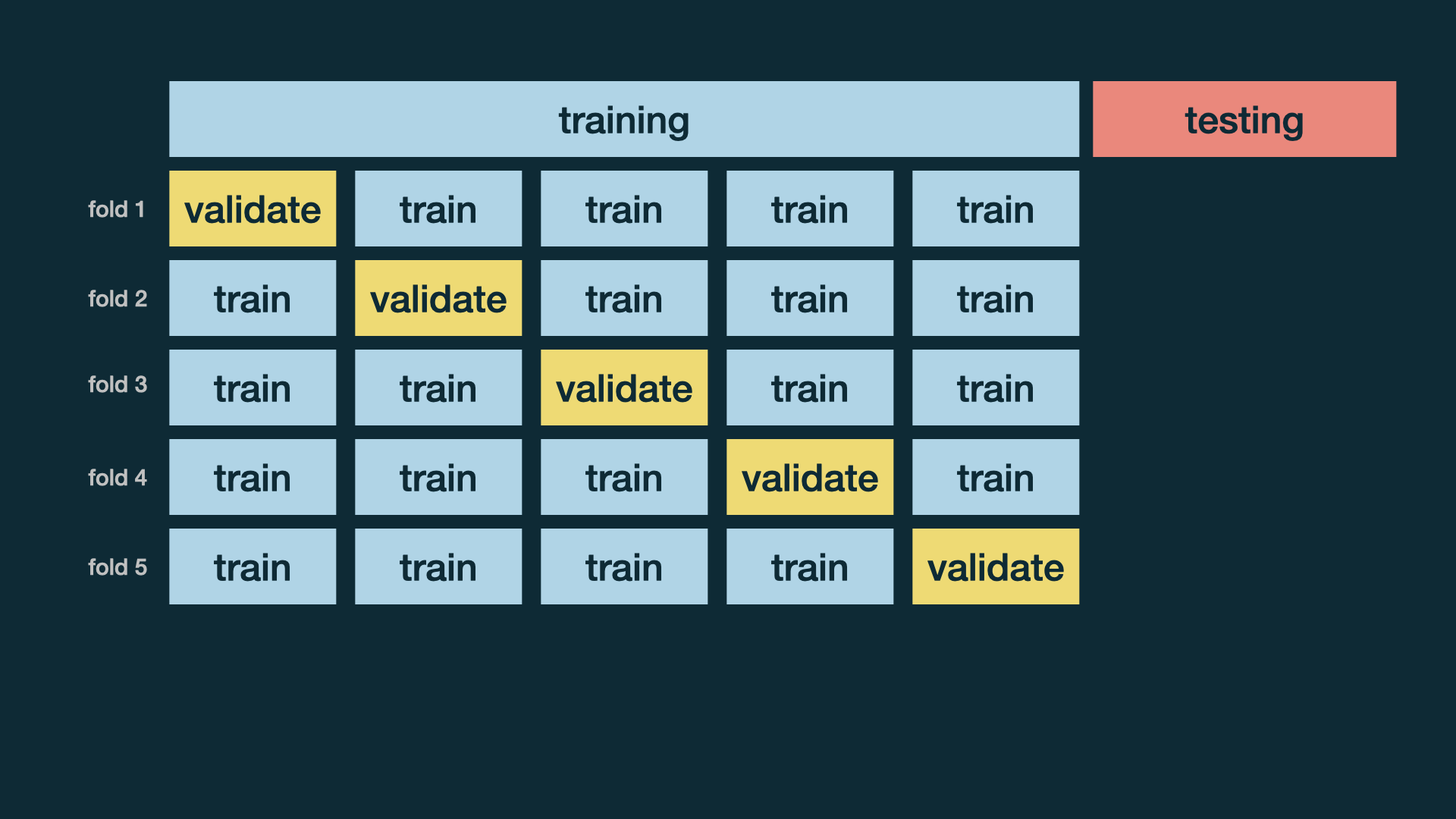
Cross validation
Split data into folds
set.seed(345)folds <- vfold_cv(office_train, v = 5)folds## # 5-fold cross-validation ## # A tibble: 5 × 2## splits id ## <list> <chr>## 1 <split [112/29]> Fold1## 2 <split [113/28]> Fold2## 3 <split [113/28]> Fold3## 4 <split [113/28]> Fold4## 5 <split [113/28]> Fold5
Fit resamples
set.seed(456)office_fit_rs <- office_wflow %>% fit_resamples(folds)office_fit_rs## # Resampling results## # 5-fold cross-validation ## # A tibble: 5 × 4## splits id .metrics .notes ## <list> <chr> <list> <list> ## 1 <split [112/29]> Fold1 <tibble [2 × 4]> <tibble [0 × 3]>## 2 <split [113/28]> Fold2 <tibble [2 × 4]> <tibble [0 × 3]>## 3 <split [113/28]> Fold3 <tibble [2 × 4]> <tibble [0 × 3]>## 4 <split [113/28]> Fold4 <tibble [2 × 4]> <tibble [0 × 3]>## 5 <split [113/28]> Fold5 <tibble [2 × 4]> <tibble [0 × 3]>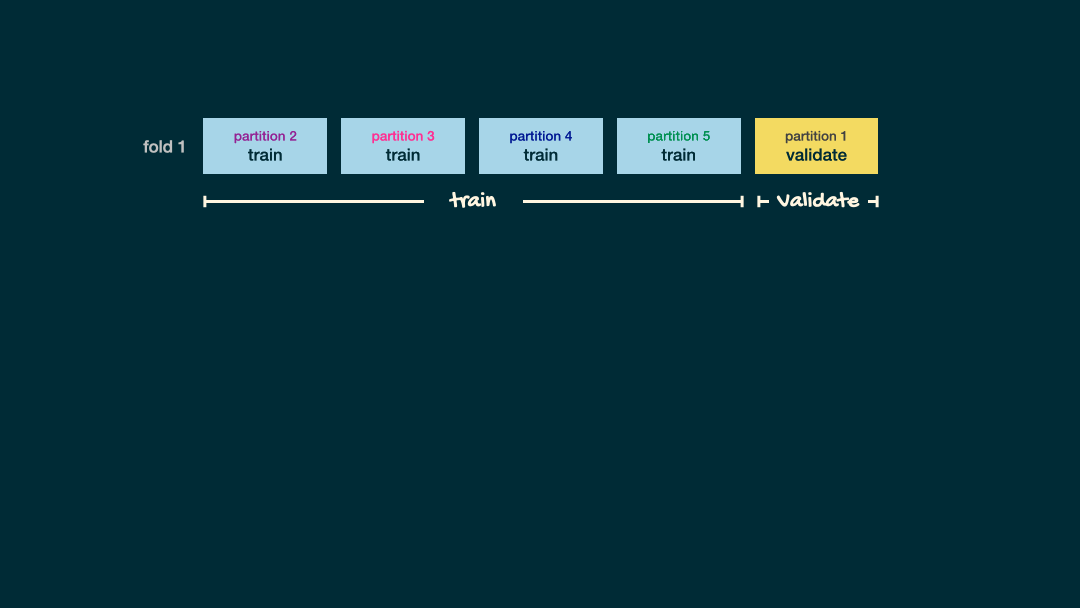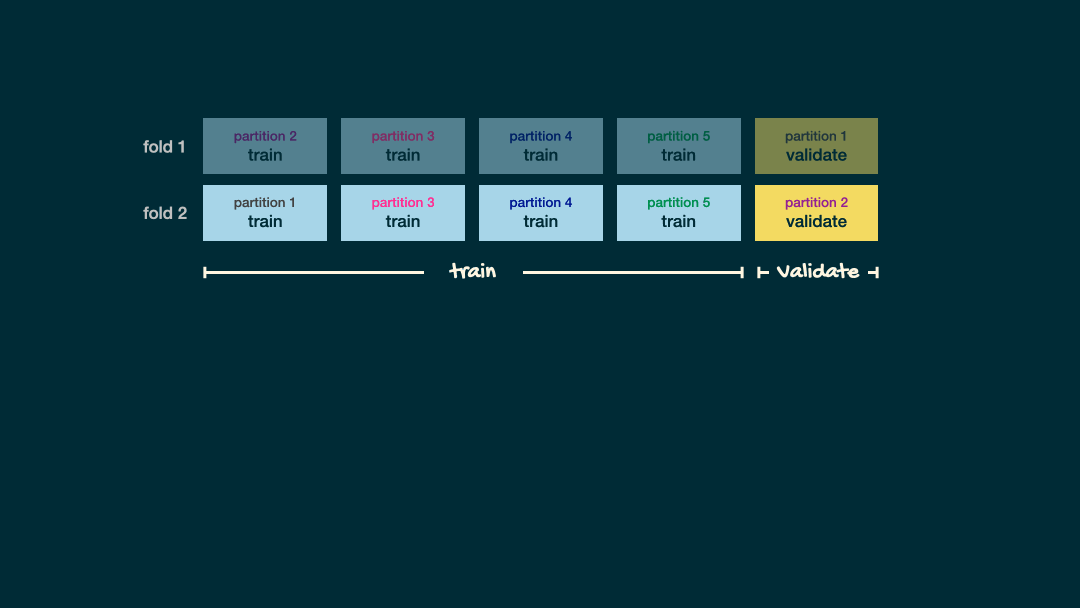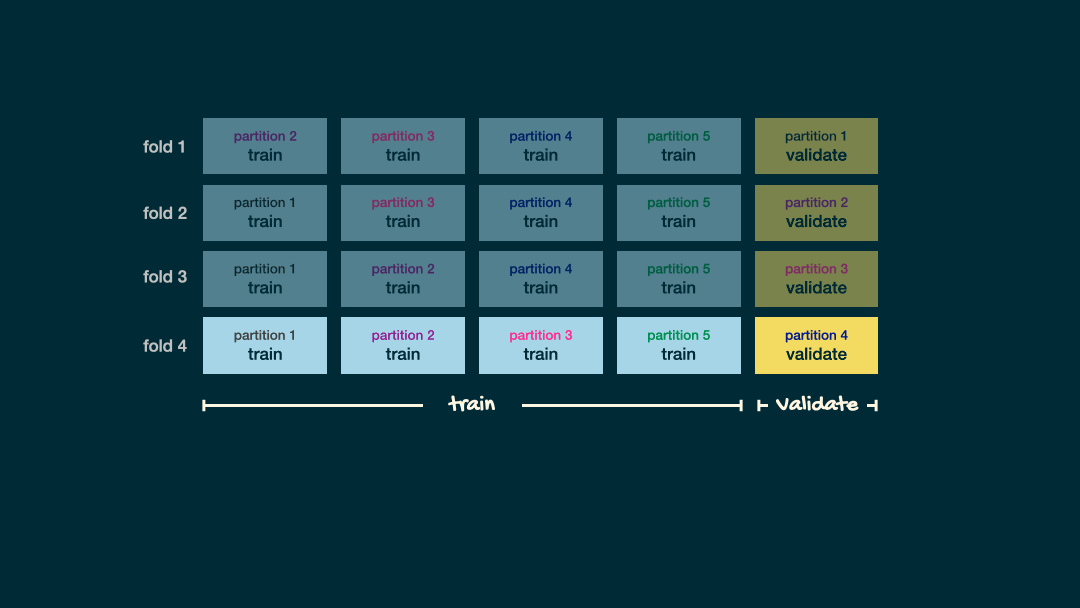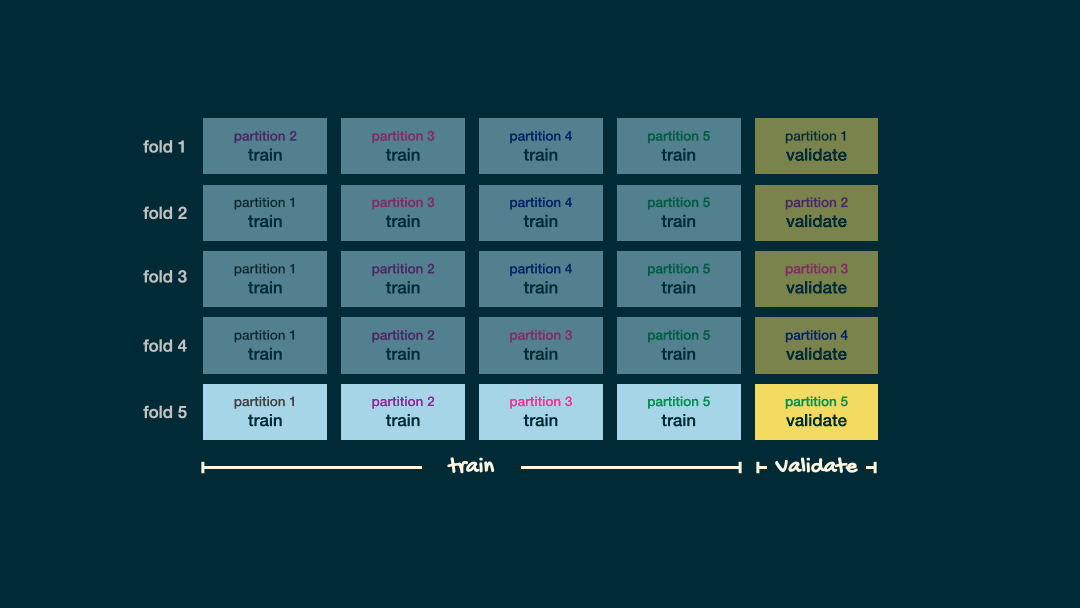
What's next?