Observed sample
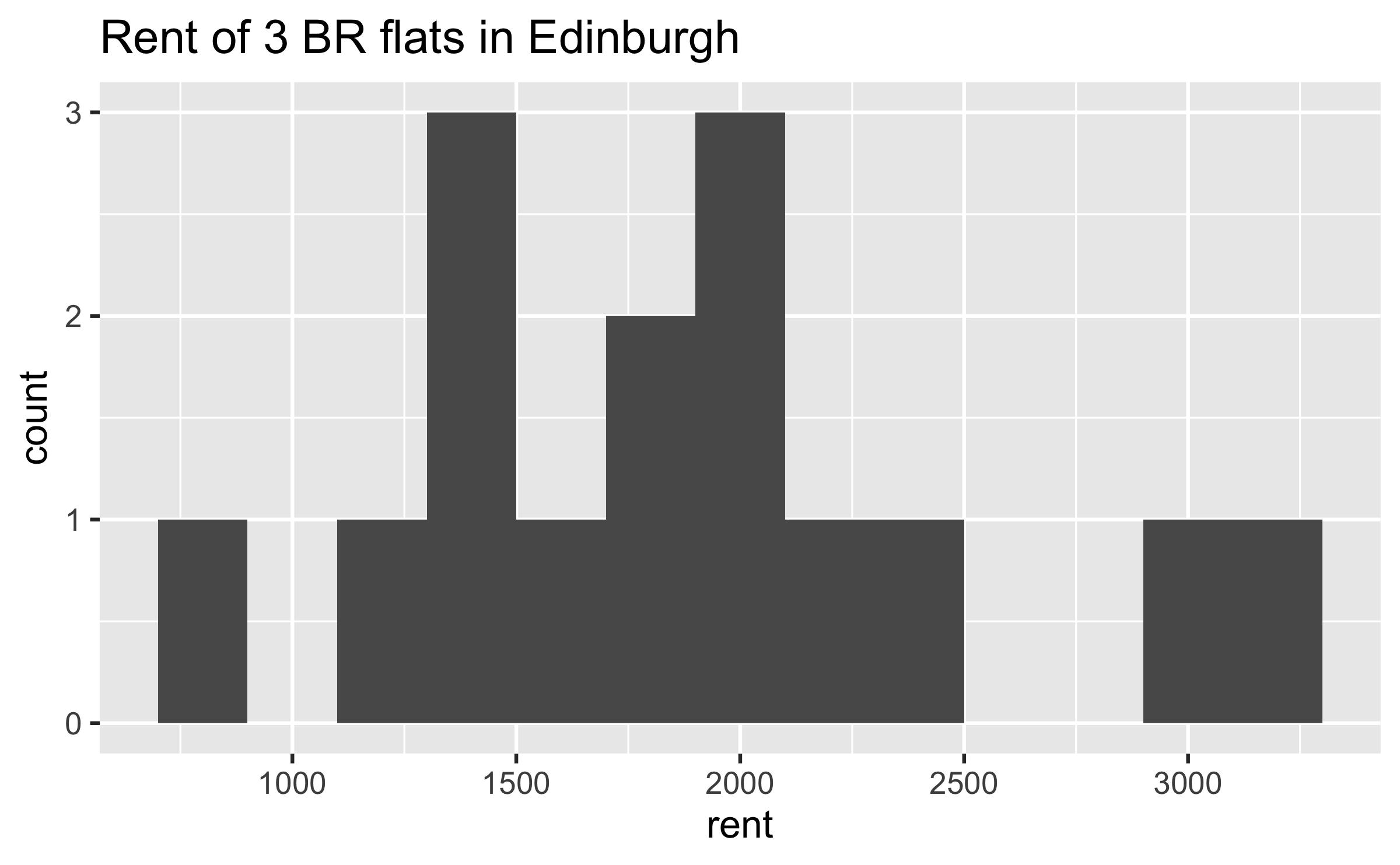
Observed sample
Sample mean ≈ £1895 😱

Bootstrap population
Generated assuming there are more flats like the ones in the observed sample... Population mean = ❓

Visualize the bootstrap distribution
ggplot(data = boot_df, mapping = aes(x = stat)) + geom_histogram(binwidth = 100) + labs(title = "Bootstrap distribution of means")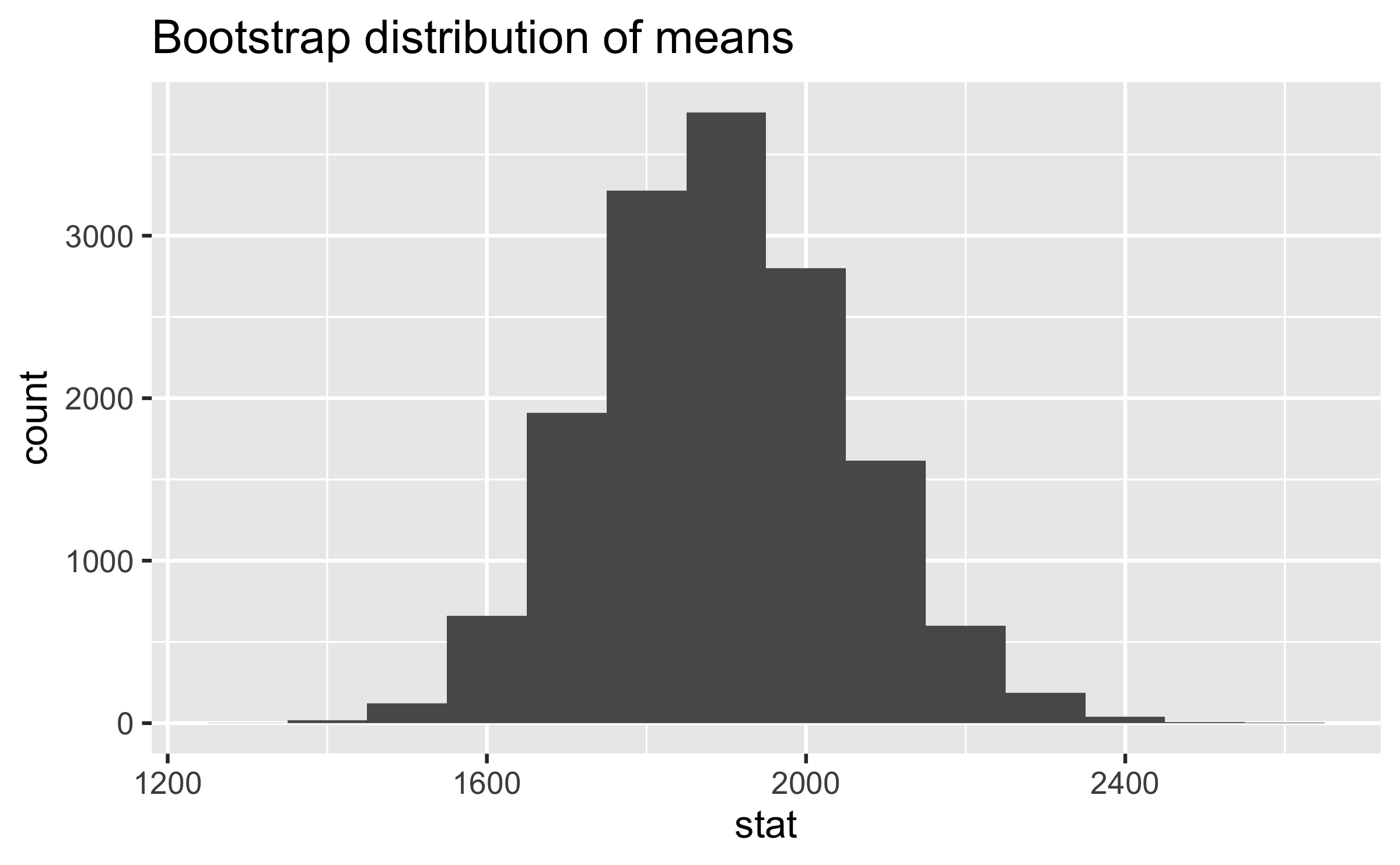
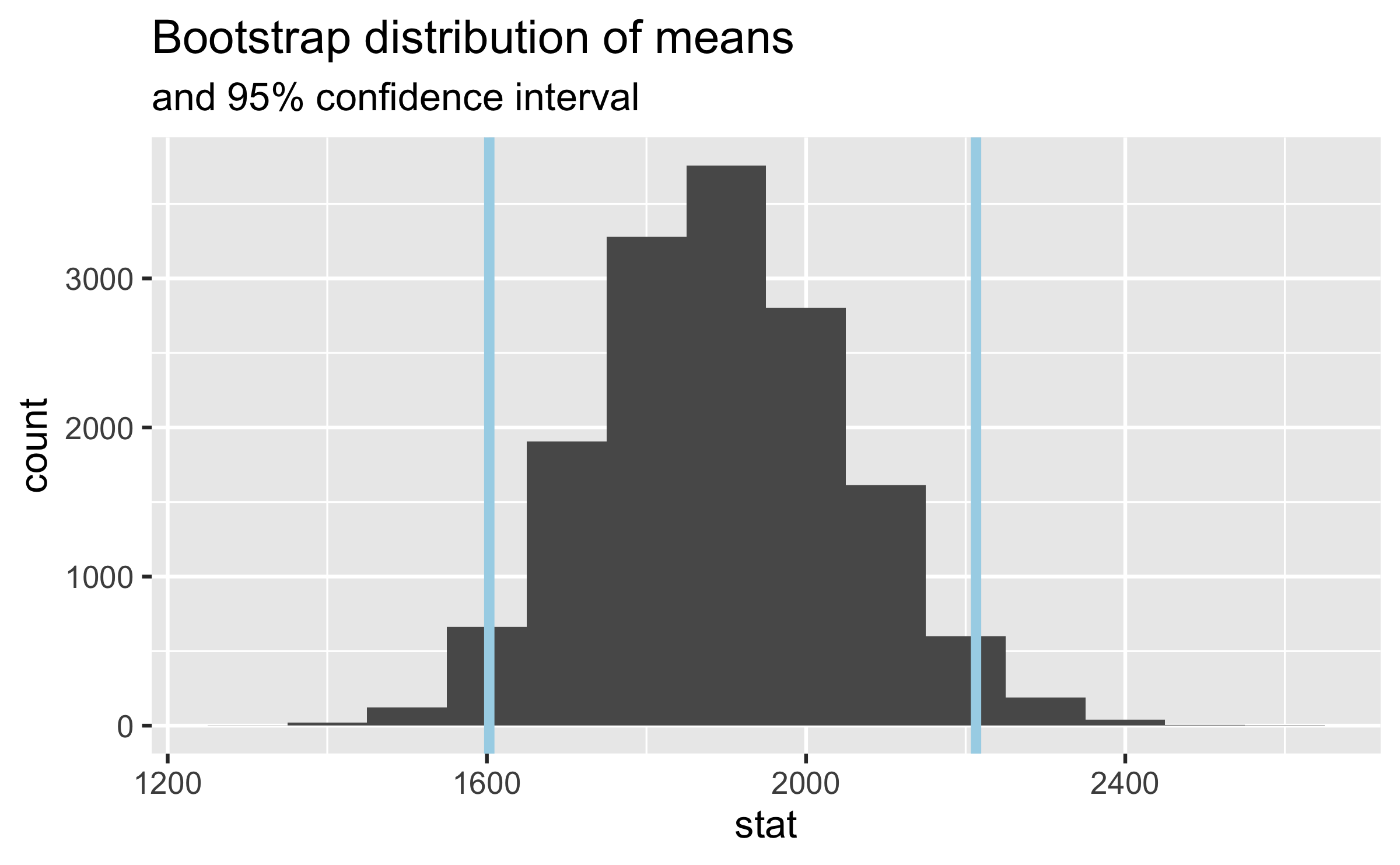
Visualize the confidence interval
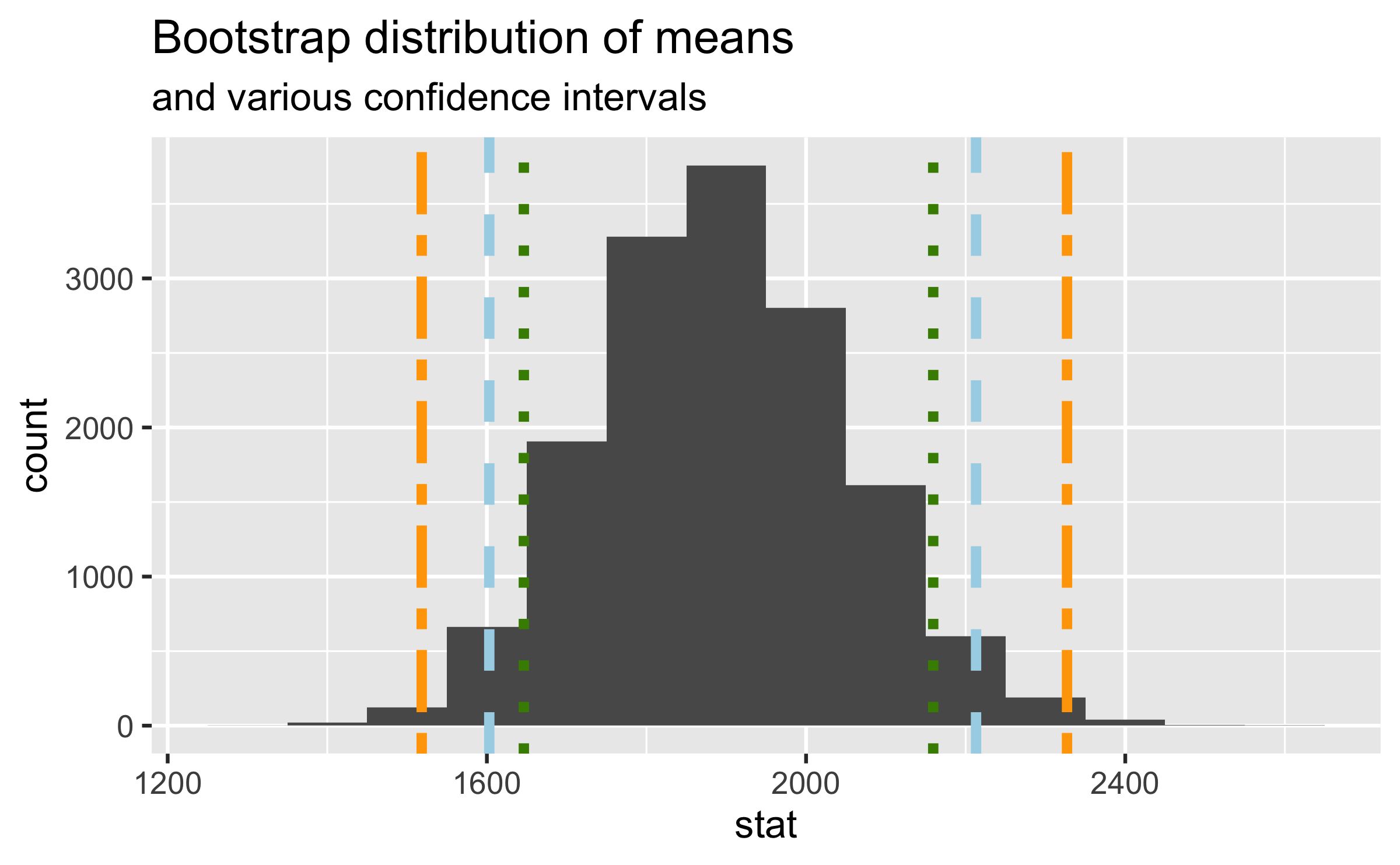
Commonly used confidence levels
Which line (orange dash/dot, blue dash, green dot) represents which confidence level?
Precision vs. accuracy
If we want to be very certain that we capture the population parameter, should we use a wider or a narrower interval? What drawbacks are associated with using a wider interval?

Precision vs. accuracy
If we want to be very certain that we capture the population parameter, should we use a wider or a narrower interval? What drawbacks are associated with using a wider interval?
How can we get best of both worlds -- high precision and high accuracy?